整理桌面
This commit is contained in:
94
node_modules/neataptic/mkdocs/templates/articles/agario.md
generated
vendored
Normal file
94
node_modules/neataptic/mkdocs/templates/articles/agario.md
generated
vendored
Normal file
@@ -0,0 +1,94 @@
|
||||
description: How to evolve neural networks to play Agar.io with Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: neuro-evolution, agar.io, Neataptic, AI
|
||||
|
||||
Agar.io is quite a simple game to play... well, for humans it is. However is it just as simple for artificial agents? In this article I will tell you how I have constructed a genetic algorithm that evolves neural networks to play in an Agario.io-like environment. The following simulation shows agents that resulted from 1000+ generations of running the algorithm:
|
||||
|
||||
<div id="field" height="500px"></div>
|
||||
|
||||
_Hover your mouse over a blob to see some more info! Source code [here](https://github.com/wagenaartje/agario-ai)_
|
||||
|
||||
As you might have noticed, the genomes are performing quite well, but far from perfect. The genomes shows human-like traits: searching food, avoiding bigger blobs and chasing smaller blobs. However sometimes one genome just runs into a bigger blob for no reason at all. That is because each genome **can only see 3 other blobs and 3 food blobs**. But above all, the settings of the GA are far from optimized. That is why I invite you to optimize the settings, and perform a pull request on this repo.
|
||||
|
||||
### The making of
|
||||
The code consists of 3 main parts: the field, the player and the genetic algorithm. In the following few paragraphs i'll go into depth on this topics, discussing my choices made. At the bottom of this article you will find a list of improvements I have thought of, but not made yet.
|
||||
|
||||
If you have any questions about the code in the linked repo, please create an issue on [this](https://github.com/wagenaartje/neataptic) repo.
|
||||
|
||||
#### The field
|
||||
The field consists of 2 different objects: food and players. Food is stationary, and has no 'brain'. Every piece of food has a static feeding value. Once food has been eaten, it just moves to a new location on the field. Players on the other hand are capable of making decisions through neural networks. They slowly decay in size when not replenished (either by eating other players or food).
|
||||
|
||||
The field has no borders; when a blob hits the left wall, it will 'teleport' to the right wall. During tests with a bordered field, the entire population of genomes tended to stick to one of the walls without ever evolving to a more flexible population. However, having borderless walls comes with a problem of which a fix has not yet been implemented: genomes that are for example near the left wall, won't detect blobs that are close to the right wall - even though the distance between the blobs can be very small.
|
||||
|
||||
**Some (configurable) settings**:
|
||||
|
||||
* There is one food blob per ~2500 pixels
|
||||
* There is one player per ~12500 pixels
|
||||
|
||||
#### The player
|
||||
The player is a simplified version of the player in the real game. A genome can't split and shoot - it can only move. The output of each genomes brain consists of merely a movement direction and movement speed.
|
||||
|
||||
Genomes can't accelerate, they immediately adapt to the speed given by their brain. They can only eat other blobs when they are 10% bigger, and they can move freely through other blobs that are less than 10% bigger. Each genome will only see the 3 closest players and the 3 closest food blobs within a certain radius.
|
||||
|
||||
**Some (configurable) settings**:
|
||||
|
||||
* A player must be 10% bigger than a blob to eat it
|
||||
* The minimal area of a player is 400 pixels
|
||||
* The maximal area of a player is 10000 pixels
|
||||
* The detection radius is 150 pixels
|
||||
* A player can see up to 3 other players in its detection radius
|
||||
* A player can see up to 3 food blobs in its detection radius
|
||||
* The maximum speed of a player is 3px/frame
|
||||
* The minimal speed of a player is 0.6px/frame
|
||||
* Every frame, the player loses 0.2% of its mass
|
||||
|
||||
#### The genetic algorithm
|
||||
The genetic algorithm is the core of the AI. In the first frame, a certain amount of players are initialized with a neural network as brain. The brains represent the population of a generation. These brains are then evolved by putting the entire population in a single playing field and letting them compete against each other. The fittest brains are moved on the next generation, the less fit brains have a high chance of being removed.
|
||||
|
||||
```javascript
|
||||
neat.sort();
|
||||
var newPopulation = [];
|
||||
|
||||
// Elitism
|
||||
for(var i = 0; i < neat.elitism; i++){
|
||||
newPopulation.push(neat.population[i]);
|
||||
}
|
||||
|
||||
// Breed the next individuals
|
||||
for(var i = 0; i < neat.popsize - neat.elitism; i++){
|
||||
newPopulation.push(neat.getOffspring());
|
||||
}
|
||||
|
||||
// Replace the old population with the new population
|
||||
neat.population = newPopulation;
|
||||
neat.mutate();
|
||||
|
||||
neat.generation++;
|
||||
startEvaluation();
|
||||
```
|
||||
|
||||
The above code shows the code run when the evaluation is finished. It is very similar to the built-in evolve() function of Neataptic, however adapted to avoid a fitness function as all genomes must be evaluated at the same time.
|
||||
|
||||
The scoring of the genomes is quite easy: when a certain amount of iterations has been reached, each genome is ranked by their area. Better performing genomes have eaten more blobs, and thus have a bigger area. This scoring is identical to the scoring in Agar.io. I have experimented with other scoring systems, but lots of them stimulated small players to finish themselves off if their score was too low for a certain amount of time.
|
||||
|
||||
**Some (configurable) settings**:
|
||||
|
||||
* An evaluation runs for 1000 frames
|
||||
* The mutation rate is 0.3
|
||||
* The elitism is 10%
|
||||
* Each genome starts with 0 hidden nodes
|
||||
* All mutation methods are allowed
|
||||
|
||||
### Issues/future improvements
|
||||
There are a couple of known issues. However, most of them linked are linked to a future improvement in some way or another.
|
||||
|
||||
**Issues**:
|
||||
|
||||
* Genomes tend to avoid hidden nodes (this is really bad)
|
||||
|
||||
**Future improvements**:
|
||||
|
||||
* Players must be able to detect close players, even if they are on the other side of the field
|
||||
* Players/food should not be spawned at locations occupied by players
|
||||
* The genetic algorithm should be able to run without any visualization
|
||||
* [.. tell me your idea!](https://github.com/wagenaartje/neataptic)
|
||||
97
node_modules/neataptic/mkdocs/templates/articles/classifycolors.md
generated
vendored
Normal file
97
node_modules/neataptic/mkdocs/templates/articles/classifycolors.md
generated
vendored
Normal file
@@ -0,0 +1,97 @@
|
||||
description: Classify different colors through genetic algorithms
|
||||
authors: Thomas Wagenaar
|
||||
keywords: color classification, genetic-algorithm, NEAT, Neataptic
|
||||
|
||||
Classifying is something a neural network can do quite well. In this article
|
||||
I will demonstrate how you can set up the evolution process of a neural network
|
||||
that learns to classify colors with Neataptic.
|
||||
|
||||
Colors:
|
||||
<label class="checkbox-inline"><input class="colors" type="checkbox" value="red" checked="true">Red</label>
|
||||
<label class="checkbox-inline"><input class="colors" type="checkbox" value="orange">Orange</label>
|
||||
<label class="checkbox-inline"><input class="colors" type="checkbox" value="yellow">Yellow</label>
|
||||
<label class="checkbox-inline"><input class="colors" type="checkbox" value="green" checked="true">Green</label>
|
||||
<label class="checkbox-inline"><input class="colors" type="checkbox" value="blue" checked="true">Blue</label>
|
||||
<label class="checkbox-inline"><input class="colors" type="checkbox" value="purple">Purple</label>
|
||||
<label class="checkbox-inline"><input class="colors" type="checkbox" value="pink">Pink</label>
|
||||
<label class="checkbox-inline"><input class="colors" type="checkbox" value="monochrome">Monochrome</label>
|
||||
|
||||
<a href="#" class="start" style="text-decoration: none"><span class="glyphicon glyphicon-play"></span> Start evolution</a>
|
||||
|
||||
<pre class="stats">Iteration: <span class="iteration">0</span> Best-fitness: <span class="bestfitness">0</span></pre>
|
||||
<div class="row" style="margin-top: -15px;">
|
||||
<div class="col-md-6">
|
||||
<center><h2 class="blocktext">Set sorted by color</h3></center>
|
||||
<div class="row set" style="padding: 30px; margin-top: -40px; padding-right: 40px;">
|
||||
</div>
|
||||
</div>
|
||||
<div class="col-md-6">
|
||||
<center><h2 class="blocktext">Set sorted by NN</h3></center>
|
||||
<div class="row fittestset" style="padding-left: 40px;">
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<hr>
|
||||
|
||||
### How it works
|
||||
The algorithm to this classification is actually _pretty_ easy. One of my biggest
|
||||
problem was generating the colors, however I stumbled upon [this](https://github.com/davidmerfield/randomColor)
|
||||
Javascript library that allows you to generate colors randomly by name - exactly
|
||||
what I needed (but it also created a problem, read below). So I used it to create
|
||||
a training set:
|
||||
|
||||
```javascript
|
||||
function createSet(){
|
||||
var set = [];
|
||||
|
||||
for(index in COLORS){
|
||||
var color = COLORS[index];
|
||||
|
||||
var randomColors = randomColor({ hue : color, count: PER_COLOR, format: 'rgb'});
|
||||
|
||||
for(var random in randomColors){
|
||||
var rgb = randomColors[random];
|
||||
random = rgb.substring(4, rgb.length-1).replace(/ /g, '').split(',');
|
||||
for(var y in random) random[y] = random[y]/255;
|
||||
|
||||
var output = Array.apply(null, Array(COLORS.length)).map(Number.prototype.valueOf, 0);
|
||||
output[index] = 1;
|
||||
|
||||
set.push({ input: random, output: output, color: color, rgb: rgb});
|
||||
}
|
||||
}
|
||||
|
||||
return set;
|
||||
}
|
||||
```
|
||||
|
||||
_COLORS_ is an array storing all color names in strings. The possible colors are
|
||||
listed above. Next, we convert this rgb string to an array and normalize the
|
||||
values between 0 and 1. Last of all, we normalize the colors using
|
||||
[one-hot encoding](https://www.quora.com/What-is-one-hot-encoding-and-when-is-it-used-in-data-science).
|
||||
Please note that the `color`and `rgb` object attributes are irrelevant for the algorithm.
|
||||
|
||||
```javascript
|
||||
network.evolve(set, {
|
||||
iterations: 1,
|
||||
mutationRate: 0.6,
|
||||
elisitm: 5,
|
||||
popSize: 100,
|
||||
mutation: methods.mutation.FFW,
|
||||
cost: methods.cost.MSE
|
||||
});
|
||||
```
|
||||
|
||||
Now we create the built-in genetic algorithm in neataptic.js. We define
|
||||
that we want to use all possible mutation methods and set the mutation rate
|
||||
higher than normal. Sprinkle in some elitism and double the default population
|
||||
size. Experiment with the parameters yourself, maybe you'll find even better parameters!
|
||||
|
||||
The fitness function is the most vital part of the algorithm. It basically
|
||||
calculates the [Mean Squared Error](https://en.wikipedia.org/wiki/Mean_squared_error)
|
||||
of the entire set. Neataptic saves the programming of this fitness calculation.
|
||||
At the same time the default `growth` parameter is used, so the networks will
|
||||
get penalized for being too large.
|
||||
|
||||
And putting together all this code will create a color classifier.
|
||||
10
node_modules/neataptic/mkdocs/templates/articles/index.md
generated
vendored
Normal file
10
node_modules/neataptic/mkdocs/templates/articles/index.md
generated
vendored
Normal file
@@ -0,0 +1,10 @@
|
||||
description: Articles featuring projects that were created with Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: Neataptic, JavaScript, library
|
||||
|
||||
Welcome to the articles page! Every now and then, articles will be posted here
|
||||
showing for what kind of projects Neataptic _could_ be used. Neataptic is
|
||||
excellent for the development of AI for browser games for example.
|
||||
|
||||
If you want to post your own article here, feel free to create a pull request
|
||||
or an isse on the [repo page](https://github.com/wagenaartje/neataptic)!
|
||||
70
node_modules/neataptic/mkdocs/templates/articles/neuroevolution.md
generated
vendored
Normal file
70
node_modules/neataptic/mkdocs/templates/articles/neuroevolution.md
generated
vendored
Normal file
@@ -0,0 +1,70 @@
|
||||
description: A list of neuro-evolution algorithms set up with Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: genetic-algorithm, Neat, JavaScript, Neataptic, neuro-evolution
|
||||
|
||||
This page shows some neuro-evolution examples. Please note that not every example
|
||||
may always be successful. More may be added in the future!
|
||||
|
||||
<div class="panel panel-warning autocollapse">
|
||||
<div class="panel-heading clickable">
|
||||
1: Uphill and downhill
|
||||
</div>
|
||||
<div class="panel-body">
|
||||
<p class="small">This neural network gets taught to increase the input by 0.2 until 1.0 is reached, then it must decrease the input by 2.0.</p>
|
||||
<button type="button" class="btn btn-default" onclick="showModal(1, 0)">Training set</button>
|
||||
<button type="button" class="btn btn-default" onclick="showModal(1, 1)">Evolve settings</button>
|
||||
<div class="btn-group">
|
||||
<button type="button" class="btn btn-primary" onclick="run(1)">Start</button>
|
||||
<button type="button" class="btn btn-default status1" style="display: none" onclick="showModal(1, 2)">Status</button>
|
||||
<button type="button" class="btn btn-danger error1" style="display: none">Error</button>
|
||||
</div>
|
||||
<svg class="example1" style="display: none"/>
|
||||
</div>
|
||||
</div>
|
||||
<div class="panel panel-warning autocollapse">
|
||||
<div class="panel-heading clickable">
|
||||
2: Count to ten
|
||||
</div>
|
||||
<div class="panel-body">
|
||||
<p class="small">This neural network gets taught to wait 9 inputs of 0, to output 1 at input number 10.</p>
|
||||
<button type="button" class="btn btn-default" onclick="showModal(2, 0)">Training set</button>
|
||||
<button type="button" class="btn btn-default" onclick="showModal(2, 1)">Evolve settings</button>
|
||||
<div class="btn-group">
|
||||
<button type="button" class="btn btn-primary" onclick="run(2)">Start</button>
|
||||
<button type="button" class="btn btn-default status2" style="display: none" onclick="showModal(2, 2)">Status</button>
|
||||
<button type="button" class="btn btn-danger error2" style="display: none">Error</button>
|
||||
</div>
|
||||
<svg class="example2" style="display: none"/>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div class="panel panel-warning autocollapse">
|
||||
<div class="panel-heading clickable">
|
||||
3: Vowel vs. consonants classification
|
||||
</div>
|
||||
<div class="panel-body">
|
||||
<p class="small">This neural network gets taught to classify if a letter of the alphabet is a vowel or not. The data is one-hot-encoded.</p>
|
||||
<button type="button" class="btn btn-default" onclick="showModal(3, 0)">Training set</button>
|
||||
<button type="button" class="btn btn-default" onclick="showModal(3, 1)">Evolve settings</button>
|
||||
<div class="btn-group">
|
||||
<button type="button" class="btn btn-primary" onclick="run(3)">Start</button>
|
||||
<button type="button" class="btn btn-default status3" style="display: none" onclick="showModal(3, 2)">Status</button>
|
||||
<button type="button" class="btn btn-danger error3" style="display: none">Error</button>
|
||||
</div>
|
||||
<svg class="example3" style="display: none"/>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div class="modal fade" id="modal" role="dialog">
|
||||
<div class="modal-dialog">
|
||||
<div class="modal-content">
|
||||
<div class="modal-header">
|
||||
<button type="button" class="close" data-dismiss="modal">×</button>
|
||||
<h4 class="modal-title"></h4>
|
||||
</div>
|
||||
<div class="modal-body">
|
||||
<pre class="modalcontent"></pre>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
82
node_modules/neataptic/mkdocs/templates/articles/playground.md
generated
vendored
Normal file
82
node_modules/neataptic/mkdocs/templates/articles/playground.md
generated
vendored
Normal file
@@ -0,0 +1,82 @@
|
||||
description: Play around with neural-networks built with Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: mutate, neural-network, machine-learning, playground, Neataptic
|
||||
|
||||
<div class="col-md-4">
|
||||
<div class="btn-group btn-group-justified">
|
||||
<div class="btn-group" role="group">
|
||||
<button type="button" class="btn btn-default" onclick="mutate(methods.mutation.SUB_NODE)">‌<span class="glyphicon glyphicon-minus"></button>
|
||||
</div>
|
||||
<div class="btn-group" role="group">
|
||||
<button type="button" class="btn btn-default">Node</button>
|
||||
</div>
|
||||
<div class="btn-group" role="group">
|
||||
<button type="button" class="btn btn-default" onclick="mutate(methods.mutation.ADD_NODE)">‌<span class="glyphicon glyphicon-plus"></button>
|
||||
</div>
|
||||
</div>
|
||||
<div class="btn-group btn-group-justified">
|
||||
<div class="btn-group" role="group">
|
||||
<button type="button" class="btn btn-default" onclick="mutate(methods.mutation.SUB_CONN)">‌<span class="glyphicon glyphicon-minus"></button>
|
||||
</div>
|
||||
<div class="btn-group" role="group">
|
||||
<button type="button" class="btn btn-default">Conn</button>
|
||||
</div>
|
||||
<div class="btn-group" role="group">
|
||||
<button type="button" class="btn btn-default" onclick="mutate(methods.mutation.ADD_CONN)">‌<span class="glyphicon glyphicon-plus"></button>
|
||||
</div>
|
||||
</div>
|
||||
<div class="btn-group btn-group-justified">
|
||||
<div class="btn-group" role="group">
|
||||
<button type="button" class="btn btn-default" onclick="mutate(methods.mutation.SUB_GATE)">‌<span class="glyphicon glyphicon-minus"></button>
|
||||
</div>
|
||||
<div class="btn-group" role="group">
|
||||
<button type="button" class="btn btn-default">Gate</button>
|
||||
</div>
|
||||
<div class="btn-group" role="group">
|
||||
<button type="button" class="btn btn-default" onclick="mutate(methods.mutation.ADD_GATE)">‌<span class="glyphicon glyphicon-plus"></button>
|
||||
</div>
|
||||
</div>
|
||||
<div class="btn-group btn-group-justified">
|
||||
<div class="btn-group" role="group">
|
||||
<button type="button" class="btn btn-default" onclick="mutate(methods.mutation.SUB_SELF_CONN)">‌<span class="glyphicon glyphicon-minus"></button>
|
||||
</div>
|
||||
<div class="btn-group" role="group">
|
||||
<button type="button" class="btn btn-default">Self-conn</button>
|
||||
</div>
|
||||
<div class="btn-group" role="group">
|
||||
<button type="button" class="btn btn-default" onclick="mutate(methods.mutation.ADD_SELF_CONN)">‌<span class="glyphicon glyphicon-plus"></button>
|
||||
</div>
|
||||
</div>
|
||||
<div class="btn-group btn-group-justified">
|
||||
<div class="btn-group" role="group">
|
||||
<button type="button" class="btn btn-default" onclick="mutate(methods.mutation.SUB_BACK_CONN)">‌<span class="glyphicon glyphicon-minus"></button>
|
||||
</div>
|
||||
<div class="btn-group" role="group">
|
||||
<button type="button" class="btn btn-default">Back-conn</button>
|
||||
</div>
|
||||
<div class="btn-group" role="group">
|
||||
<button type="button" class="btn btn-default" onclick="mutate(methods.mutation.ADD_BACK_CONN)">‌<span class="glyphicon glyphicon-plus"></button>
|
||||
</div>
|
||||
</div>
|
||||
<div class="input-group" style="margin-bottom: 15px;">
|
||||
<span class="input-group-addon">input1</span>
|
||||
<input type="number" class="form-control input1" value=0>
|
||||
</div>
|
||||
<div class="input-group" style="margin-bottom: 15px;">
|
||||
<span class="input-group-addon">input2</span>
|
||||
<input type="number" class="form-control input2" value=1>
|
||||
</div>
|
||||
<div class="btn-group btn-group-justified">
|
||||
<div class="btn-group" role="group">
|
||||
<button class="btn btn-warning" onclick="activate()">Activate</button>
|
||||
</div>
|
||||
</div>
|
||||
<pre>Output: <span class="output"></span></pre>
|
||||
|
||||
</div>
|
||||
<div class="col-md-8">
|
||||
<div class="panel panel-default">
|
||||
<svg class="draw" width="100%" height="60%"/>
|
||||
</div>
|
||||
|
||||
</div>
|
||||
135
node_modules/neataptic/mkdocs/templates/articles/targetseeking.md
generated
vendored
Normal file
135
node_modules/neataptic/mkdocs/templates/articles/targetseeking.md
generated
vendored
Normal file
@@ -0,0 +1,135 @@
|
||||
description: Neural agents learn to seek targets through neuro-evolution
|
||||
authors: Thomas Wagenaar
|
||||
keywords: target seeking, AI, genetic-algorithm, NEAT, Neataptic
|
||||
|
||||
In the simulation below, neural networks that have been evolved through roughly
|
||||
100 generations try to seek a target. Their goal is to stay as close to the target
|
||||
as possible at all times. If you want to see how one of these networks looks like,
|
||||
check out the [complete simulation](https://wagenaartje.github.io/target-seeking-ai/).
|
||||
|
||||
<div id="field" height="500px">
|
||||
</div>
|
||||
|
||||
_Click on the field to relocate the target! Source code [here](https://wagenaartje.github.io/target-seeking-ai/)._
|
||||
|
||||
The neural agents are actually performing really well. At least one agent will have
|
||||
'solved the problem' after roughly 20 generations. That is because the base of the solution
|
||||
is quite easy: one of the inputs of the neural networks is the angle to the target, so all it
|
||||
has to do is output some value that is similar to this input value. This can easily be done
|
||||
through the identity activation function, but surprisingly, most agents in the simulation above
|
||||
tend to avoid this function.
|
||||
|
||||
You can check out the topology of the networks [here](https://wagenaartje.github.io/target-seeking-ai/).
|
||||
If you manage to evolve the genomes quicker or better than this simulation with different settings, please
|
||||
perform a pull request on [this](https://wagenaartje.github.io/target-seeking-ai/) repo.
|
||||
|
||||
### The making of
|
||||
|
||||
In the previous article I have gone more into depth on the environment of the algorithm, but in this article
|
||||
I will focus more on the settings and inputs/outputs of the algorithm itself.
|
||||
|
||||
|
||||
If you have any questions about the code in the linked repo, please create an issue on [this](https://github.com/wagenaartje/neataptic) repo.
|
||||
|
||||
|
||||
### The agents
|
||||
The agents' task is very simple. They have to get in the vicinity of the target which is set to about
|
||||
100 pixels, once they are in that vicinity, each agents' score will be increased proportionally `(100 - dist)``
|
||||
to the distance. There is one extra though: for every node in the agents' network, the score of the agent will
|
||||
be decreased. This has two reasons; 1. networks shouldn't overfit the solution and 2. having smaller networks
|
||||
reduces computation power.
|
||||
|
||||
Agents have some kind of momentum. They don't have mass, but they do have acceleration, so it takes a small
|
||||
amount of time for a agent to reach the top speed in a certain direction.
|
||||
|
||||
|
||||
**Each agent has the following inputs**:
|
||||
|
||||
* Its own speed in the x-axis
|
||||
* Its own speed in the y-axis
|
||||
* The targets' speed in the x-axis
|
||||
* The targets' speed in the y-axis
|
||||
* The angle towards the target
|
||||
* The distance to the target
|
||||
|
||||
|
||||
The output of each agent is just the desired movement direction.
|
||||
|
||||
There is no kind of collision, except for the walls of the fields. In the future, it might be interesting to
|
||||
add collisions between multiple agents and/or the target to reveal some new tactics. This would require the
|
||||
agent to know the location of surrounding agents.
|
||||
|
||||
### The target
|
||||
The target is fairly easy. It's programmed to switch direction every now and then by a random amount. There
|
||||
is one important thing however: _the target moves with half the speed of the agents_, this makes sure
|
||||
that agents always have the ability to catch up with the target. Apart from that, the physics for the target
|
||||
are similar to the agents' physics.
|
||||
|
||||
### The genetic algorithm
|
||||
|
||||
The genetic algorithm is the core of the AI. In the first frame, a certain
|
||||
amount of players are initialized with a neural network as brain. The brains
|
||||
represent the population of a generation. These brains are then evolved by
|
||||
putting the entire population in óne playing field and letting them compete
|
||||
against each other. The fittest brains are moved on the next generation,
|
||||
the less fit brains have a high chance of being removed.
|
||||
|
||||
```javascript
|
||||
// Networks shouldn't get too big
|
||||
for(var genome in neat.population){
|
||||
genome = neat.population[genome];
|
||||
genome.score -= genome.nodes.length * SCORE_RADIUS / 10;
|
||||
}
|
||||
|
||||
// Sort the population by score
|
||||
neat.sort();
|
||||
|
||||
// Draw the best genome
|
||||
drawGraph(neat.population[0].graph($('.best').width(), $('.best').height()), '.best', false);
|
||||
|
||||
// Init new pop
|
||||
var newPopulation = [];
|
||||
|
||||
// Elitism
|
||||
for(var i = 0; i < neat.elitism; i++){
|
||||
newPopulation.push(neat.population[i]);
|
||||
}
|
||||
|
||||
// Breed the next individuals
|
||||
for(var i = 0; i < neat.popsize - neat.elitism; i++){
|
||||
newPopulation.push(neat.getOffspring());
|
||||
}
|
||||
|
||||
// Replace the old population with the new population
|
||||
neat.population = newPopulation;
|
||||
neat.mutate();
|
||||
|
||||
neat.generation++;
|
||||
startEvaluation();
|
||||
```
|
||||
|
||||
The above code shows the code run when the evaluation is finished. It is very similar
|
||||
to the built-in `evolve()` function of Neataptic, however adapted to avoid a fitness
|
||||
function as all genomes must be evaluated at the same time.
|
||||
|
||||
The scoring of the genomes is quite easy: when a certain amount of iterations has been reached,
|
||||
each genome is ranked by their final score. Genomes with a higher score have a small amount of nodes
|
||||
and have been close to the target throughout the iteration.
|
||||
|
||||
**Some (configurable) settings**:
|
||||
|
||||
* An evaluation runs for 250 frames
|
||||
* The mutation rate is 0.3
|
||||
* The elitism is 10%
|
||||
* Each genome starts with 0 hidden nodes
|
||||
* All mutation methods are allowed
|
||||
|
||||
### Issues/future improvements
|
||||
* ... none yet! [Tell me your ideas!](https://github.com/wagenaartje/neataptic)
|
||||
|
||||
**Forks**
|
||||
|
||||
* [corpr8's fork](https://corpr8.github.io/neataptic-targetseeking-tron/)
|
||||
gives each neural agent its own acceleration, as well as letting each arrow
|
||||
remain in the same place after each generation. This creates a much more
|
||||
'fluid' process.
|
||||
230
node_modules/neataptic/mkdocs/templates/docs/NEAT.md
generated
vendored
Normal file
230
node_modules/neataptic/mkdocs/templates/docs/NEAT.md
generated
vendored
Normal file
@@ -0,0 +1,230 @@
|
||||
description: Documentation of the Neuro-evolution of Augmenting Topologies technique in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: neuro-evolution, NEAT, genetic=algorithm
|
||||
|
||||
The built-in NEAT class allows you create evolutionary algorithms with just a few lines of code. If you want to evolve neural networks to conform a given dataset, check out [this](https://github.com/wagenaartje/neataptic/wiki/Network#functions) page. The following code is from the [Agario-AI](https://github.com/wagenaartje/agario-ai) built with Neataptic.
|
||||
|
||||
```javascript
|
||||
/** Construct the genetic algorithm */
|
||||
function initNeat(){
|
||||
neat = new Neat(
|
||||
1 + PLAYER_DETECTION * 3 + FOOD_DETECTION * 2,
|
||||
2,
|
||||
null,
|
||||
{
|
||||
mutation: methods.mutation.ALL
|
||||
popsize: PLAYER_AMOUNT,
|
||||
mutationRate: MUTATION_RATE,
|
||||
elitism: Math.round(ELITISM_PERCENT * PLAYER_AMOUNT),
|
||||
network: new architect.Random(
|
||||
1 + PLAYER_DETECTION * 3 + FOOD_DETECTION * 2,
|
||||
START_HIDDEN_SIZE,
|
||||
2
|
||||
)
|
||||
}
|
||||
);
|
||||
|
||||
if(USE_TRAINED_POP) neat.population = population;
|
||||
}
|
||||
|
||||
/** Start the evaluation of the current generation */
|
||||
function startEvaluation(){
|
||||
players = [];
|
||||
highestScore = 0;
|
||||
|
||||
for(var genome in neat.population){
|
||||
genome = neat.population[genome];
|
||||
new Player(genome);
|
||||
}
|
||||
}
|
||||
|
||||
/** End the evaluation of the current generation */
|
||||
function endEvaluation(){
|
||||
console.log('Generation:', neat.generation, '- average score:', neat.getAverage());
|
||||
|
||||
neat.sort();
|
||||
var newPopulation = [];
|
||||
|
||||
// Elitism
|
||||
for(var i = 0; i < neat.elitism; i++){
|
||||
newPopulation.push(neat.population[i]);
|
||||
}
|
||||
|
||||
// Breed the next individuals
|
||||
for(var i = 0; i < neat.popsize - neat.elitism; i++){
|
||||
newPopulation.push(neat.getOffspring());
|
||||
}
|
||||
|
||||
// Replace the old population with the new population
|
||||
neat.population = newPopulation;
|
||||
neat.mutate();
|
||||
|
||||
neat.generation++;
|
||||
startEvaluation();
|
||||
}
|
||||
```
|
||||
|
||||
You might also want to check out the [target-seeking project](https://github.com/wagenaartje/target-seeking-ai) built with Neataptic.
|
||||
|
||||
## Options
|
||||
The constructor comes with various options. The constructor works as follows:
|
||||
|
||||
```javascript
|
||||
new Neat(input, output, fitnessFunction, options); // options should be an object
|
||||
```
|
||||
|
||||
Every generation, each genome will be tested on the `fitnessFunction`. The
|
||||
fitness function should return a score (a number). Through evolution, the
|
||||
genomes will try to _maximize_ the output of the fitness function.
|
||||
|
||||
Negative scores are allowed.
|
||||
|
||||
You can provide the following options in an object for the `options` argument:
|
||||
|
||||
<details>
|
||||
<summary>popsize</summary>
|
||||
Sets the population size of each generation. Default is 50.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>elitism</summary>
|
||||
Sets the <a href="https://www.researchgate.net/post/What_is_meant_by_the_term_Elitism_in_the_Genetic_Algorithm">elitism</a> of every evolution loop. Default is 0.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>provenance</summary>
|
||||
Sets the provenance of the genetic algorithm. Provenance means that during every evolution, the given amount of genomes will be inserted which all have the original
|
||||
network template (which is <code>Network(input,output)</code> when no <code>network</code> option is given). Default is 0.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>mutation</summary>
|
||||
Sets the allowed <a href="https://wagenaartje.github.io/neataptic/docs/methods/mutation/">mutation methods</a> used in the evolutionary process. Must be an array (e.g. <code>[methods.mutation.ADD_NODE, methods.mutation.SUB_NODE]</code>). Default mutation methods are all non-recurrent mutation methods. A random mutation method will be chosen from the array when mutation occrus.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>selection</summary>
|
||||
Sets the allowed <a href="https://wagenaartje.github.io/neataptic/docs/methods/selection/">selection method</a> used in the evolutionary process. Must be a single method (e.g. <code>Selection.FITNESS_PROPORTIONATE</code>). Default is <code>FITNESS_PROPORTIONATE</code>.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>crossover</summary>
|
||||
Sets the allowed crossover methods used in the evolutionary process. Must be an array. <b>disabled as of now</b>
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>fitnessPopulation</summary>
|
||||
If set to <code>true</code>, you will have to specify a fitness function that
|
||||
takes an array of genomes as input and sets their <code>.score</code> property.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>mutationRate</summary>
|
||||
Sets the mutation rate. If set to <code>0.3</code>, 30% of the new population will be mutated. Default is <code>0.3</code>.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>mutationAmount</summary>
|
||||
If mutation occurs (<code>randomNumber < mutationRate</code>), sets the amount of times a mutation method will be applied to the network. Default is <code>1</code>.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>network</summary>
|
||||
If you want to start the algorithm from a specific network, specify your network here.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>equal</summary>
|
||||
If set to true, all networks will be viewed equal during crossover. This stimulates more diverse network architectures. Default is <code>false</code>.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>clear</summary>
|
||||
Clears the context of the network before activating the fitness function. Should be applied to get consistent outputs from recurrent networks. Default is <code>false</code>.
|
||||
</details>
|
||||
|
||||
## Properties
|
||||
There are only a few properties
|
||||
|
||||
<details>
|
||||
<summary>input</summary>
|
||||
The amount of input neurons each genome has
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>output</summary>
|
||||
The amount of output neurons each genome has
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>fitness</summary>
|
||||
The fitness function that is used to evaluate genomes
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>generation</summary>
|
||||
Generation counter
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>population</summary>
|
||||
An array containing all the genomes of the current generation
|
||||
</details>
|
||||
|
||||
## Functions
|
||||
There are a few built-in functions. For the client, only `getFittest()` and `evolve()` is important. In the future, there will be a combination of backpropagation and evolution. Stay tuned
|
||||
|
||||
<details>
|
||||
<summary>createPool()</summary>
|
||||
Initialises the first set of genomes. Should not be called manually.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary><i>async</i> evolve()</summary>
|
||||
Loops the generation through a evaluation, selection, crossover and mutation process.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary><i>async</i> evaluate()</summary>
|
||||
Evaluates the entire population by passing on the genome to the fitness function and taking the score.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>sort()</summary>
|
||||
Sorts the entire population by score. Should be called after <code>evaluate()</code>
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>getFittest()</summary>
|
||||
Returns the fittest genome (highest score) of the current generation
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>mutate()</summary>
|
||||
Mutates genomes in the population, each genome has <code>mutationRate</code> chance of being mutated.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>getOffspring()</summary>
|
||||
This function selects two genomes from the population with <code>getParent()</code>, and returns the offspring from those parents.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>getAverage()</summary>
|
||||
Returns the average fitness of the current population
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>getParent()</summary>
|
||||
Returns a parent selected using one of the selection methods provided. Should be called after evaluation. Should not be called manually.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>export()</summary>
|
||||
Exports the current population of the set up algorithm to a list containing json objects of the networks. Can be used later with <code>import(json)</code> to reload the population
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>import(json)</summary>
|
||||
Imports population from a json. Must be an array of networks that have converted to json (with <code>myNetwork.toJSON()</code>)
|
||||
</details>
|
||||
10
node_modules/neataptic/mkdocs/templates/docs/architecture/architecture.md
generated
vendored
Normal file
10
node_modules/neataptic/mkdocs/templates/docs/architecture/architecture.md
generated
vendored
Normal file
@@ -0,0 +1,10 @@
|
||||
If you want to built your completely custom neural network; this is the place to be.
|
||||
You can build your network from the bottom, using nodes and connections, or you can
|
||||
ease up the process by using groups and layers.
|
||||
|
||||
* [Connection](connection.md)
|
||||
* [Node](node.md)
|
||||
* [Group](group.md)
|
||||
* [Layer](layer.md)
|
||||
* [Network](network.md)
|
||||
* [Construct](construct.md)
|
||||
30
node_modules/neataptic/mkdocs/templates/docs/architecture/connection.md
generated
vendored
Normal file
30
node_modules/neataptic/mkdocs/templates/docs/architecture/connection.md
generated
vendored
Normal file
@@ -0,0 +1,30 @@
|
||||
description: Documentation of the Connection instance in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: connection, neural-network, architecture, synapse, weight
|
||||
|
||||
A connection instance defines the connection between two nodes. All you have to do is pass on a from and to node, and optionally a weight.
|
||||
|
||||
```javascript
|
||||
var B = new Node();
|
||||
var C = new Node();
|
||||
var connection = new Connection(A, B, 0.5);
|
||||
```
|
||||
|
||||
Connection properties:
|
||||
|
||||
Property | contains
|
||||
-------- | --------
|
||||
from | connection origin node
|
||||
to | connection destination node
|
||||
weight | the weight of the connection
|
||||
gater | the node gating this connection
|
||||
gain | for gating, gets multiplied with weight
|
||||
|
||||
### Connection methods
|
||||
There are three connection methods:
|
||||
|
||||
* **methods.connection.ALL_TO_ALL** connects all nodes from group `x` to all nodes from group `y`
|
||||
* **methods.connection.ALL_TO_ELSE** connects every node from group `x` to all nodes in the same group except itself
|
||||
* **methods.connection.ONE_TO_ONE** connects every node in group `x` to one node in group `y`
|
||||
|
||||
Every one of these connection methods can also be used on the group itself! (`x.connect(x, METHOD)`)
|
||||
47
node_modules/neataptic/mkdocs/templates/docs/architecture/construct.md
generated
vendored
Normal file
47
node_modules/neataptic/mkdocs/templates/docs/architecture/construct.md
generated
vendored
Normal file
@@ -0,0 +1,47 @@
|
||||
description: Documentation on how to construct your own network with Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: neural-network, architecture, node, build, connection
|
||||
|
||||
|
||||
For example, I want to have a network that looks like a square:
|
||||
|
||||
```javascript
|
||||
var A = new Node();
|
||||
var B = new Node();
|
||||
var C = new Node();
|
||||
var D = new Node();
|
||||
|
||||
// Create connections
|
||||
A.connect(B);
|
||||
A.connect(C);
|
||||
B.connect(D);
|
||||
C.connect(D);
|
||||
|
||||
// Construct a network
|
||||
var network = architect.Construct([A, B, C, D]);
|
||||
```
|
||||
|
||||
And voila, basically a square, but stretched out, right?
|
||||
|
||||
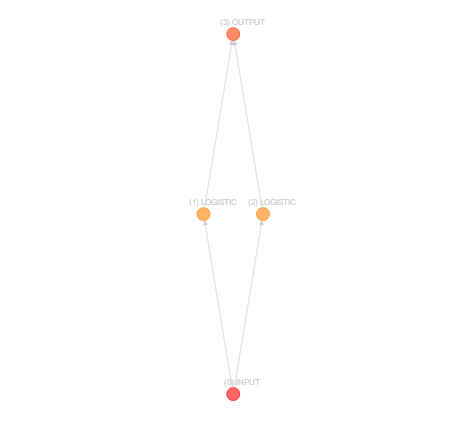
|
||||
|
||||
The `construct()` function looks for nodes that have no input connections, and labels them as an input node. The same for output nodes: it looks for nodes without an output connection (and gating connection), and labels them as an output node!
|
||||
|
||||
**You can also create networks with groups!** This speeds up the creation process and saves lines of code.
|
||||
|
||||
```javascript
|
||||
// Initialise groups of nodes
|
||||
var A = new Group(4);
|
||||
var B = new Group(2);
|
||||
var C = new Group(6);
|
||||
|
||||
// Create connections between the groups
|
||||
A.connect(B);
|
||||
A.connect(C);
|
||||
B.connect(C);
|
||||
|
||||
// Construct a network
|
||||
var network = architect.Construct([A, B, C, D]);
|
||||
```
|
||||
|
||||
Keep in mind that you must always specify your input groups/nodes in **activation order**. Input and output nodes will automatically get sorted out, but all hidden nodes will be activated in the order that they were given.
|
||||
115
node_modules/neataptic/mkdocs/templates/docs/architecture/group.md
generated
vendored
Normal file
115
node_modules/neataptic/mkdocs/templates/docs/architecture/group.md
generated
vendored
Normal file
@@ -0,0 +1,115 @@
|
||||
description: Documentation of the Group instance in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: group, neurons, nodes, neural-network, activation
|
||||
|
||||
|
||||
A group instance denotes a group of nodes. Beware: once a group has been used to construct a network, the groups will fall apart into individual nodes. They are purely for the creation and development of networks. A group can be created like this:
|
||||
|
||||
```javascript
|
||||
// A group with 5 nodes
|
||||
var A = new Group(5);
|
||||
```
|
||||
|
||||
Group properties:
|
||||
|
||||
Property | contains
|
||||
-------- | --------
|
||||
nodes | an array of all nodes in the group
|
||||
connections | dictionary with connections
|
||||
|
||||
### activate
|
||||
Will activate all the nodes in the network.
|
||||
|
||||
```javascript
|
||||
myGroup.activate();
|
||||
|
||||
// or (array length must be same length as nodes in group)
|
||||
myGroup.activate([1, 0, 1]);
|
||||
```
|
||||
|
||||
### propagate
|
||||
Will backpropagate all nodes in the group, make sure the group receives input from another group or node!
|
||||
|
||||
```javascript
|
||||
myGroup.propagate(rate, momentum, target);
|
||||
```
|
||||
|
||||
The target argument is optional. An example would be:
|
||||
|
||||
```javascript
|
||||
var A = new Group(2);
|
||||
var B = new Group(3);
|
||||
|
||||
A.connect(B);
|
||||
|
||||
A.activate([1,0]); // set the input
|
||||
B.activate(); // get the output
|
||||
|
||||
// Then teach the network with learning rate and wanted output
|
||||
B.propagate(0.3, 0.9, [0,1]);
|
||||
```
|
||||
|
||||
The default value for momentum is `0`. Read more about momentum on the
|
||||
[regularization page](../methods/regularization.md).
|
||||
|
||||
### connect
|
||||
Creates connections between this group and another group or node. There are different connection methods for groups, check them out [here](connection.md).
|
||||
|
||||
```javascript
|
||||
var A = new Group(4);
|
||||
var B = new Group(5);
|
||||
|
||||
A.connect(B, methods.connection.ALL_TO_ALL); // specifying a method is optional
|
||||
```
|
||||
|
||||
### disconnect
|
||||
(not yet implemented)
|
||||
|
||||
### gate
|
||||
Makes the nodes in a group gate an array of connections between two other groups. You have to specify a gating method, which can be found [here](../methods/gating.md).
|
||||
|
||||
```javascript
|
||||
var A = new Group(2);
|
||||
var B = new Group(6);
|
||||
|
||||
var connections = A.connect(B);
|
||||
|
||||
var C = new Group(2);
|
||||
|
||||
// Gate the connections between groups A and B
|
||||
C.gate(connections, methods.gating.INPUT);
|
||||
```
|
||||
|
||||
### set
|
||||
Sets the properties of all nodes in the group to the given values, e.g.:
|
||||
|
||||
```javascript
|
||||
var group = new Group(4);
|
||||
|
||||
// All nodes in 'group' now have a bias of 1
|
||||
group.set({bias: 1});
|
||||
```
|
||||
|
||||
### disconnect
|
||||
Disconnects the group from another group or node. Can be twosided.
|
||||
|
||||
```javascript
|
||||
var A = new Group(4);
|
||||
var B = new Node();
|
||||
|
||||
// Connect them
|
||||
A.connect(B);
|
||||
|
||||
// Disconnect them
|
||||
A.disconnect(B);
|
||||
|
||||
// Twosided connection
|
||||
A.connect(B);
|
||||
B.connect(A);
|
||||
|
||||
// Disconnect from both sides
|
||||
A.disconnect(B, true);
|
||||
```
|
||||
|
||||
### clear
|
||||
Clears the context of the group. Useful for predicting timeseries with LSTM's.
|
||||
77
node_modules/neataptic/mkdocs/templates/docs/architecture/layer.md
generated
vendored
Normal file
77
node_modules/neataptic/mkdocs/templates/docs/architecture/layer.md
generated
vendored
Normal file
@@ -0,0 +1,77 @@
|
||||
description: Documentation of the Layer instance in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: LSTM, GRU, architecture, neural-network, recurrent
|
||||
|
||||
|
||||
Layers are pre-built architectures that allow you to combine different network
|
||||
architectures into óne network. At this moment, there are 3 layers (more to come soon!):
|
||||
|
||||
```javascript
|
||||
Layer.Dense
|
||||
Layer.LSTM
|
||||
Layer.GRU
|
||||
Layer.Memory
|
||||
```
|
||||
|
||||
Check out the options and details for each layer below.
|
||||
|
||||
### Constructing your own network with layers
|
||||
You should always start your network with a `Dense` layer and always end it with
|
||||
a `Dense` layer. You can connect layers with each other just like you can connect
|
||||
nodes and groups with each other. This is an example of a custom architecture
|
||||
built with layers:
|
||||
|
||||
```javascript
|
||||
var input = new Layer.Dense(1);
|
||||
var hidden1 = new Layer.LSTM(5);
|
||||
var hidden2 = new Layer.GRU(1);
|
||||
var output = new Layer.Dense(1);
|
||||
|
||||
// connect however you want
|
||||
input.connect(hidden1);
|
||||
hidden1.connect(hidden2);
|
||||
hidden2.connect(output);
|
||||
|
||||
var network = architect.Construct([input, hidden1, hidden2, output]);
|
||||
```
|
||||
|
||||
### Layer.Dense
|
||||
The dense layer is a regular layer.
|
||||
|
||||
```javascript
|
||||
var layer = new Layer.Dense(size);
|
||||
```
|
||||
|
||||
### Layer.LSTM
|
||||
The LSTM layer is very useful for detecting and predicting patterns over long
|
||||
time lags. This is a recurrent layer. More info? Check out the [LSTM](../builtins/lstm.md) page.
|
||||
|
||||
```javascript
|
||||
var layer = new Layer.LSTM(size);
|
||||
```
|
||||
|
||||
Be aware that using `Layer.LSTM` is worse than using `architect.LSTM`. See issue [#25](https://github.com/wagenaartje/neataptic/issues/25).
|
||||
|
||||
### Layer.GRU
|
||||
The GRU layer is similar to the LSTM layer, however it has no memory cell and only
|
||||
two gates. It is also a recurrent layer that is excellent for timeseries prediction.
|
||||
More info? Check out the [GRU](../builtins/gru.md) page.
|
||||
|
||||
```javascript
|
||||
var layer = new Layer.GRU(size);
|
||||
```
|
||||
|
||||
### Layer.Memory
|
||||
The Memory layer is very useful if you want your network to remember a number of
|
||||
previous inputs in an absolute way. For example, if you set the `memory` option to
|
||||
3, it will remember the last 3 inputs in the same state as they were inputted.
|
||||
|
||||
```javascript
|
||||
var layer = new Layer.Memory(size, memory);
|
||||
```
|
||||
|
||||
The input layer to the memory layer should always have the same size as the memory size.
|
||||
The memory layer will output a total of `size * memory` values.
|
||||
|
||||
> This page is incomplete. There is no description on the functions you can use
|
||||
on this instance yet. Feel free to add the info (check out src/layer.js)
|
||||
269
node_modules/neataptic/mkdocs/templates/docs/architecture/network.md
generated
vendored
Normal file
269
node_modules/neataptic/mkdocs/templates/docs/architecture/network.md
generated
vendored
Normal file
@@ -0,0 +1,269 @@
|
||||
description: Documentation of the network model in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: neural-network, recurrent, layers, neurons, connections, input, output, activation
|
||||
|
||||
Networks are very easy to create. All you have to do is specify an `input` size and an `output` size.
|
||||
|
||||
```javascript
|
||||
// Network with 2 input neurons and 1 output neuron
|
||||
var myNetwork = new Network(2, 1);
|
||||
|
||||
// If you want to create multi-layered networks
|
||||
var myNetwork = new architect.Perceptron(5, 20, 10, 5, 1);
|
||||
```
|
||||
|
||||
If you want to create more advanced networks, check out the 'Networks' tab on the left.
|
||||
|
||||
|
||||
|
||||
### Functions
|
||||
Check out the [train](../important/train.md) and [evolve](../important/evolve.md) functions on their separate pages!
|
||||
|
||||
<details>
|
||||
<summary>activate</summary>
|
||||
Activates the network. It will activate all the nodes in activation order and produce an output.
|
||||
|
||||
<pre>
|
||||
// Create a network
|
||||
var myNetwork = new Network(3, 2);
|
||||
|
||||
myNetwork.activate([0.8, 1, 0.21]); // gives: [0.49, 0.51]
|
||||
</pre>
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>noTraceActivate</summary>
|
||||
Activates the network. It will activate all the nodes in activation order and produce an output.
|
||||
Does not calculate traces, so backpropagation is not possible afterwards. That makes
|
||||
it faster than the regular `activate` function.
|
||||
|
||||
<pre>
|
||||
// Create a network
|
||||
var myNetwork = new Network(3, 2);
|
||||
|
||||
myNetwork.noTraceActivate([0.8, 1, 0.21]); // gives: [0.49, 0.51]
|
||||
</pre>
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>propagate</summary>
|
||||
This function allows you to teach the network. If you want to do more complex
|
||||
training, use the <code>network.train()</code> function. The arguments for
|
||||
this function are:
|
||||
|
||||
<pre>
|
||||
myNetwork.propagate(rate, momentum, update, target);
|
||||
</pre>
|
||||
|
||||
Where target is optional. The default value of momentum is `0`. Read more about
|
||||
momentum on the [regularization page](../methods/regularization.md). If you run
|
||||
propagation without setting update to true, then the weights won't update. So if
|
||||
you run propagate 3x with `update: false`, and then 1x with `update: true` then
|
||||
the weights will be updated after the last propagation, but the deltaweights of
|
||||
the first 3 propagation will be included too.
|
||||
|
||||
<pre>
|
||||
var myNetwork = new Network(1,1);
|
||||
|
||||
// This trains the network to function as a NOT gate
|
||||
for(var i = 0; i < 1000; i++){
|
||||
network.activate([0]);
|
||||
network.propagate(0.2, 0, true, [1]);
|
||||
|
||||
network.activate([1]);
|
||||
network.propagate(0.3, 0, true, [0]);
|
||||
}
|
||||
</pre>
|
||||
|
||||
The above example teaches the network to output <code>[1]</code> when input <code>[0]</code> is given and the other way around. Main usage:
|
||||
|
||||
<pre>
|
||||
network.activate(input);
|
||||
network.propagate(learning_rate, momentum, update_weights, desired_output);
|
||||
</pre>
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>merge</summary>
|
||||
The merge functions takes two networks, the output size of <code>network1</code> should be the same size as the input of <code>network2</code>. Merging will always be one to one to conserve the purpose of the networks. Usage:
|
||||
|
||||
<pre>
|
||||
var XOR = architect.Perceptron(2,4,1); // assume this is a trained XOR
|
||||
var NOT = architect.Perceptron(1,2,1); // assume this is a trained NOT
|
||||
|
||||
// combining these will create an XNOR
|
||||
var XNOR = Network.merge(XOR, NOT);
|
||||
</pre>
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>connect</summary>
|
||||
Connects two nodes in the network:
|
||||
|
||||
<pre>
|
||||
myNetwork.connect(myNetwork.nodes[4], myNetwork.nodes[5]);
|
||||
</pre>
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>remove</summary>
|
||||
Removes a node from a network, all its connections will be redirected. If it gates a connection, the gate will be removed.
|
||||
|
||||
<pre>
|
||||
myNetwork = new architect.Perceptron(1,4,1);
|
||||
|
||||
// Remove a node
|
||||
myNetwork.remove(myNetwork.nodes[2]);
|
||||
</pre>
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>disconnect</summary>
|
||||
Disconnects two nodes in the network:
|
||||
|
||||
<pre>
|
||||
myNetwork.disconnect(myNetwork.nodes[4], myNetwork.nodes[5]);
|
||||
// now node 4 does not have an effect on the output of node 5 anymore
|
||||
</pre>
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>gate</summary>
|
||||
Makes a network node gate a connection:
|
||||
|
||||
<pre>
|
||||
myNetwork.gate(myNetwork.nodes[1], myNetwork.connections[5]
|
||||
</pre>
|
||||
|
||||
Now the weight of connection 5 is multiplied with the activation of node 1!
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>ungate</summary>
|
||||
Removes a gate from a connection:
|
||||
|
||||
<pre>
|
||||
myNetwork = new architect.Perceptron(1, 4, 2);
|
||||
|
||||
// Gate a connection
|
||||
myNetwork.gate(myNetwork.nodes[2], myNetwork.connections[5]);
|
||||
|
||||
// Remove the gate from the connection
|
||||
myNetwork.ungate(myNetwork.connections[5]);
|
||||
</pre>
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>mutate</summary>
|
||||
Mutates the network. See [mutation methods](../methods/mutation.md).
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>serialize</summary>
|
||||
Serializes the network to 3 <code>Float64Arrays</code>. Used for transferring
|
||||
networks to other threads fast.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>toJSON/fromJSON</summary>
|
||||
Networks can be stored as JSON's and then restored back:
|
||||
|
||||
<pre>
|
||||
var exported = myNetwork.toJSON();
|
||||
var imported = Network.fromJSON(exported);
|
||||
</pre>
|
||||
|
||||
<code>imported</code> will be a new instance of <code>Network</code> that is an exact clone of <code>myNetwork</code>.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>standalone</summary>
|
||||
Networks can be used in Javascript without the need of the Neataptic library,
|
||||
this function will transform your network into a function accompanied by arrays.
|
||||
|
||||
<pre>
|
||||
var myNetwork = new architect.Perceptron(2,4,1);
|
||||
myNetwork.activate([0,1]); // [0.24775789809]
|
||||
|
||||
// a string
|
||||
var standalone = myNetwork.standalone();
|
||||
|
||||
// turns your network into an 'activate' function
|
||||
eval(standalone);
|
||||
|
||||
// calls the standalone function
|
||||
activate([0,1]);// [0.24775789809]
|
||||
</pre>
|
||||
|
||||
The reason an `eval` is being called is because the standalone can't be a simply
|
||||
a function, it needs some kind of global memory. You can easily copy and paste the
|
||||
result of `standalone` in any JS file and run the `activate` function!
|
||||
|
||||
Note that this is still in development, so for complex networks, it might not be
|
||||
precise.
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>crossOver</summary>
|
||||
Creates a new 'baby' network from two parent networks. Networks are not required to have the same size, however input and output size should be the same!
|
||||
|
||||
<pre>
|
||||
// Initialise two parent networks
|
||||
var network1 = new architect.Perceptron(2, 4, 3);
|
||||
var network2 = new architect.Perceptron(2, 4, 5, 3);
|
||||
|
||||
// Produce an offspring
|
||||
var network3 = Network.crossOver(network1, network2);
|
||||
</pre>
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>set</summary>
|
||||
Sets the properties of all nodes in the network to the given values, e.g.:
|
||||
|
||||
<pre>
|
||||
var network = new architect.Random(4, 4, 1);
|
||||
|
||||
// All nodes in 'network' now have a bias of 1
|
||||
network.set({bias: 1});
|
||||
</pre>
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>clear</summary>
|
||||
Clears the context of the network. Useful for predicting timeseries with LSTM's. `clear()` has little to no effecton regular NN, use on RNN's!
|
||||
</details>
|
||||
|
||||
### Properties
|
||||
Each network only has a small number of properties.
|
||||
|
||||
<details>
|
||||
<summary>input</summary>
|
||||
Input size of the network
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>output</summary>
|
||||
Output size of the network
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>nodes</summary>
|
||||
Array of nodes
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>connections</summary>
|
||||
Array of connections
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>gates</summary>
|
||||
Array of gated connections
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>selfconns</summary>
|
||||
Array of self connections
|
||||
</details>
|
||||
203
node_modules/neataptic/mkdocs/templates/docs/architecture/node.md
generated
vendored
Normal file
203
node_modules/neataptic/mkdocs/templates/docs/architecture/node.md
generated
vendored
Normal file
@@ -0,0 +1,203 @@
|
||||
description: Documentation of the Node instance in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: node, neuron, neural-network, activation, bias
|
||||
|
||||
|
||||
Nodes are the key to neural networks. They provide the non-linearity in the output. A node can be created as follows:
|
||||
|
||||
```javascript
|
||||
var node = new Node();
|
||||
```
|
||||
|
||||
Node properties:
|
||||
|
||||
Property | contains
|
||||
-------- | --------
|
||||
bias | the bias when calculating state
|
||||
squash | activation function
|
||||
type | 'input', 'hidden' or 'output', should not be used manually (setting to 'constant' will disable bias/weight changes)
|
||||
activation | activation value
|
||||
connections | dictionary of in and out connections
|
||||
old | stores the previous activation
|
||||
state | stores the state (before being squashed)
|
||||
|
||||
### activate
|
||||
Actives the node. Calculates the state from all the input connections, adds the bias, and 'squashes' it.
|
||||
|
||||
```javascript
|
||||
var node = new Node();
|
||||
node.activate(); // 0.4923128591923
|
||||
```
|
||||
|
||||
### noTraceActivate
|
||||
Actives the node. Calculates the state from all the input connections, adds the bias, and 'squashes' it.
|
||||
Does not calculate traces, so this can't be used to backpropagate afterwards.
|
||||
That's also why it's quite a bit faster than regular `activate`.
|
||||
|
||||
```javascript
|
||||
var node = new Node();
|
||||
node.noTraceActivate(); // 0.4923128591923
|
||||
```
|
||||
|
||||
### propagate
|
||||
After an activation, you can teach the node what should have been the correct
|
||||
output (a.k.a. train). This is done by backpropagating the error. To use the
|
||||
propagate method you have to provide a learning rate, and a target value
|
||||
(float between 0 and 1).
|
||||
|
||||
The arguments you can pass on are as follows:
|
||||
|
||||
```javascript
|
||||
myNode.propagate(learningRate, momentum, update, target);
|
||||
```
|
||||
|
||||
The target argument is optional. The default value of momentum is `0`. Read more
|
||||
about momentum on the [regularization page](../methods/regularization.md). If you run
|
||||
propagation without setting update to true, then the weights won't update. So if
|
||||
you run propagate 3x with `update: false`, and then 1x with `update: true` then
|
||||
the weights will be updated after the last propagation, but the deltaweights of
|
||||
the first 3 propagation will be included too. For example, this is how you can
|
||||
train node B to activate 0 when node A activates 1:
|
||||
|
||||
```javascript
|
||||
var A = new Node();
|
||||
var B = new Node('output');
|
||||
A.connect(B);
|
||||
|
||||
var learningRate = .3;
|
||||
var momentum = 0;
|
||||
|
||||
for(var i = 0; i < 20000; i++)
|
||||
{
|
||||
// when A activates 1
|
||||
A.activate(1);
|
||||
|
||||
// train B to activate 0
|
||||
B.activate();
|
||||
B.propagate(learningRate, momentum, true, 0);
|
||||
}
|
||||
|
||||
// test it
|
||||
A.activate(1);
|
||||
B.activate(); // 0.006540565760853365
|
||||
```
|
||||
|
||||
|
||||
### connect
|
||||
A node can project a connection to another node or group (i.e. connect node A with node B). Here is how it's done:
|
||||
|
||||
```javascript
|
||||
var A = new Node();
|
||||
var B = new Node();
|
||||
A.connect(B); // A now projects a connection to B
|
||||
|
||||
// But you can also connect nodes to groups
|
||||
var C = new Group(4);
|
||||
|
||||
B.connect(C); // B now projects a connection to all nodes in C
|
||||
```
|
||||
|
||||
A neuron can also connect to itself, creating a selfconnection:
|
||||
|
||||
```javascript
|
||||
var A = new Node();
|
||||
A.connect(A); // A now connects to itself
|
||||
```
|
||||
|
||||
### disconnect
|
||||
Removes the projected connection from this node to the given node.
|
||||
|
||||
```javascript
|
||||
var A = new Node();
|
||||
var B = new Node();
|
||||
A.connect(B); // A now projects a connection to B
|
||||
|
||||
A.disconnect(B); // no connection between A and B anymore
|
||||
```
|
||||
|
||||
If the nodes project a connection to each other, you can also disconnect both connections at once:
|
||||
|
||||
```javascript
|
||||
var A = new Node();
|
||||
var B = new Node();
|
||||
A.connect(B); // A now projects a connection to B
|
||||
B.connect(A); // B now projects a connection to A
|
||||
|
||||
|
||||
// A.disconnect(B) only disconnects A to B, so use
|
||||
A.disconnect(B, true); // or B.disconnect(A, true)
|
||||
```
|
||||
|
||||
### gate
|
||||
Neurons can gate connections. This means that the activation value of a neuron has influence on the value transported through a connection. You can either give an array of connections or just a connection as an argument.
|
||||
|
||||
```javascript
|
||||
var A = new Node();
|
||||
var B = new Node();
|
||||
var C = new Node();
|
||||
|
||||
var connections = A.connect(B);
|
||||
|
||||
// Now gate the connection(s)
|
||||
C.gate(connections);
|
||||
```
|
||||
|
||||
Now the weight of the connection from A to B will always be multiplied by the activation of node C.
|
||||
|
||||
### ungate
|
||||
You can also remove a gate from a connection.
|
||||
|
||||
```javascript
|
||||
var A = new Node();
|
||||
var B = new Node();
|
||||
var C = new Node();
|
||||
|
||||
var connections = A.connect(B);
|
||||
|
||||
// Now gate the connection(s)
|
||||
C.gate(connections);
|
||||
|
||||
// Now ungate those connections
|
||||
C.ungate(connections);
|
||||
```
|
||||
|
||||
### isProjectingTo
|
||||
Checks if the node is projecting a connection to another neuron.
|
||||
|
||||
```javascript
|
||||
var A = new Node();
|
||||
var B = new Node();
|
||||
var C = new Node();
|
||||
A.connect(B);
|
||||
B.connect(C);
|
||||
|
||||
A.isProjectingTo(B); // true
|
||||
A.isProjectingTo(C); // false
|
||||
```
|
||||
|
||||
### isProjectedBy
|
||||
Checks if the node is projected by another node.
|
||||
|
||||
```javascript
|
||||
var A = new Node();
|
||||
var B = new Node();
|
||||
var C = new Node();
|
||||
A.connect(B);
|
||||
B.connect(C);
|
||||
|
||||
A.isProjectedBy(C); // false
|
||||
B.isProjectedBy(A); // true
|
||||
```
|
||||
|
||||
### toJSON/fromJSON
|
||||
Nodes can be stored as JSON's and then restored back:
|
||||
|
||||
```javascript
|
||||
var exported = myNode.toJSON();
|
||||
var imported = Network.fromJSON(exported);
|
||||
```
|
||||
|
||||
imported will be a new instance of Node that is an exact clone of myNode.
|
||||
|
||||
### clear
|
||||
Clears the context of the node. Useful for predicting timeseries with LSTM's.
|
||||
11
node_modules/neataptic/mkdocs/templates/docs/builtins/builtins.md
generated
vendored
Normal file
11
node_modules/neataptic/mkdocs/templates/docs/builtins/builtins.md
generated
vendored
Normal file
@@ -0,0 +1,11 @@
|
||||
If you are unfamiliar with building networks layer by layer, you can use the
|
||||
preconfigured networks. These networks will also be built layer by layer behind
|
||||
the screens, but for the user they are all a simple one line function. At this
|
||||
moment, Neataptic offers 6 preconfigured networks.
|
||||
|
||||
* [GRU](gru.md)
|
||||
* [Hopfield](hopfield.md)
|
||||
* [LSTM](lstm.md)
|
||||
* [NARX](narx.md)
|
||||
* [Perceptron](perceptron.md)
|
||||
* [Random](random.md)
|
||||
49
node_modules/neataptic/mkdocs/templates/docs/builtins/gru.md
generated
vendored
Normal file
49
node_modules/neataptic/mkdocs/templates/docs/builtins/gru.md
generated
vendored
Normal file
@@ -0,0 +1,49 @@
|
||||
description: How to use the Gated Recurrent Unit network in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: recurrent, neural-network, GRU, architecture
|
||||
|
||||
> Please be warned: GRU is still being tested, it might not always work for your dataset.
|
||||
|
||||
The Gated Recurrent Unit network is very similar to the LSTM network. GRU networks have óne gate less and no selfconnections. Similarly to LSTM's, GRU's are well-suited to classify, process and predict time series when there are very long time lags of unknown size between important events.
|
||||
|
||||
<img src="http://colah.github.io/posts/2015-08-Understanding-LSTMs/img/LSTM3-var-GRU.png" width="100%"/>
|
||||
|
||||
To use this architecture you have to set at least one input node, one gated recurrent unit assembly, and an output node. The gated recurrent unit assembly consists of seven nodes: input, update gate, inverse update gate, reset gate, memorycell, output and previous output memory.
|
||||
|
||||
```javascript
|
||||
var myLSTM = new architect.GRU(2,6,1);
|
||||
```
|
||||
|
||||
Also you can set many layers of gated recurrent units:
|
||||
|
||||
```javascript
|
||||
var myLSTM = new architect.GRU(2, 4, 4, 4, 1);
|
||||
```
|
||||
|
||||
The above network has 3 hidden layers, with 4 GRU assemblies each. It has two inputs and óne output.
|
||||
|
||||
While training sequences or timeseries prediction to a GRU, make sure you set the `clear` option to true while training. Additionally, through trial and error, I have discovered that using a lower rate than normal works best for GRU networks (e.g. `0.1` instead of `0.3`).
|
||||
|
||||
This is an example of training the sequence XOR gate to a a GRU network:
|
||||
|
||||
```js
|
||||
var trainingSet = [
|
||||
{ input: [0], output: [0]},
|
||||
{ input: [1], output: [1]},
|
||||
{ input: [1], output: [0]},
|
||||
{ input: [0], output: [1]},
|
||||
{ input: [0], output: [0]}
|
||||
];
|
||||
|
||||
var network = new architect.GRU(1,1,1);
|
||||
|
||||
// Train a sequence: 00100100..
|
||||
network.train(trainingSet, {
|
||||
log: 1,
|
||||
rate: 0.1,
|
||||
error: 0.005,
|
||||
iterations: 3000,
|
||||
clear: true
|
||||
});
|
||||
```
|
||||
[Run it here yourself!](https://jsfiddle.net/dzywa15x/)
|
||||
22
node_modules/neataptic/mkdocs/templates/docs/builtins/hopfield.md
generated
vendored
Normal file
22
node_modules/neataptic/mkdocs/templates/docs/builtins/hopfield.md
generated
vendored
Normal file
@@ -0,0 +1,22 @@
|
||||
description: How to use the Hopfield network in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: feed-forward, neural-network, hopfield, architecture
|
||||
|
||||
> This network might be removed soon
|
||||
|
||||
The hopfield architecture is excellent for remembering patterns. Given an input, it will output the most similar pattern it was trained. The output will always be binary, due to the usage of the `Activation.STEP` function.
|
||||
|
||||
```javascript
|
||||
var network = architect.Hopfield(10);
|
||||
var trainingSet = [
|
||||
{ input: [0, 1, 0, 1, 0, 1, 0, 1, 0, 1], output: [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] },
|
||||
{ input: [1, 1, 1, 1, 1, 0, 0, 0, 0, 0], output: [1, 1, 1, 1, 1, 0, 0, 0, 0, 0] }
|
||||
];
|
||||
|
||||
network.train(trainingSet);
|
||||
|
||||
network.activate([0,1,0,1,0,1,0,1,1,1]); // [0, 1, 0, 1, 0, 1, 0, 1, 0, 1]
|
||||
network.activate([1,1,1,1,1,0,0,1,0,0]); // [1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
|
||||
```
|
||||
|
||||
The input for the training set must always be the same as the output.
|
||||
39
node_modules/neataptic/mkdocs/templates/docs/builtins/lstm.md
generated
vendored
Normal file
39
node_modules/neataptic/mkdocs/templates/docs/builtins/lstm.md
generated
vendored
Normal file
@@ -0,0 +1,39 @@
|
||||
description: How to use the Long Short-Term Memory network in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: recurrent, neural-network, LSTM, architecture
|
||||
|
||||
The [long short-term memory](http://en.wikipedia.org/wiki/Long_short_term_memory) is an architecture well-suited to learn from experience to classify, process and predict time series when there are very long time lags of unknown size between important events.
|
||||
|
||||
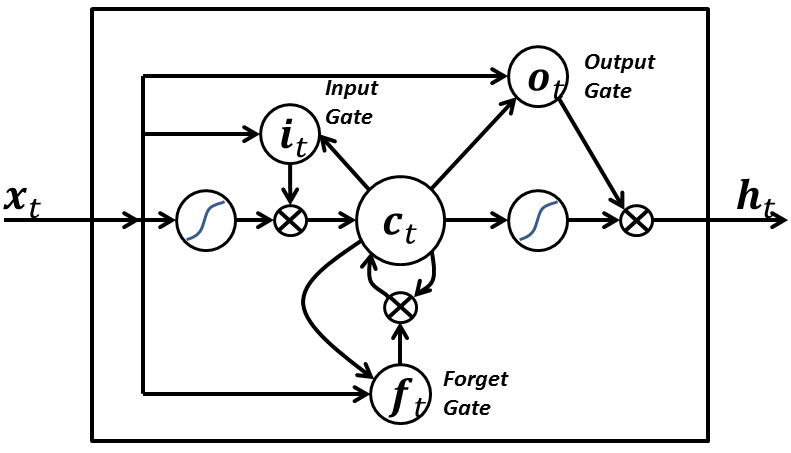
|
||||
|
||||
To use this architecture you have to set at least one input node, one memory block assembly (consisting of four nodes: input gate, memory cell, forget gate and output gate), and an output node.
|
||||
|
||||
```javascript
|
||||
var myLSTM = new architect.LSTM(2,6,1);
|
||||
```
|
||||
|
||||
Also you can set many layers of memory blocks:
|
||||
|
||||
```javascript
|
||||
var myLSTM = new architect.LSTM(2, 4, 4, 4, 1);
|
||||
```
|
||||
|
||||
That LSTM network has 3 memory block assemblies, with 4 memory cells each, and their own input gates, memory cells, forget gates and output gates.
|
||||
|
||||
You can pass options if desired like so:
|
||||
|
||||
```javascript
|
||||
var options = {
|
||||
memoryToMemory: false, // default is false
|
||||
outputToMemory: false, // default is false
|
||||
outputToGates: false, // default is false
|
||||
inputToOutput: true, // default is true
|
||||
inputToDeep: true // default is true
|
||||
};
|
||||
|
||||
var myLSTM = new architect.LSTM(2, 4, 4, 4, 1, options);
|
||||
```
|
||||
|
||||
While training sequences or timeseries prediction to a LSTM, make sure you set the `clear` option to true while training. [See an example of sequence prediction here.](https://jsfiddle.net/9t2787k5/4/)
|
||||
|
||||
This is an example of character-by-character typing by an LSTM: [JSFiddle](https://jsfiddle.net/k23zbf0f/8/)
|
||||
48
node_modules/neataptic/mkdocs/templates/docs/builtins/narx.md
generated
vendored
Normal file
48
node_modules/neataptic/mkdocs/templates/docs/builtins/narx.md
generated
vendored
Normal file
@@ -0,0 +1,48 @@
|
||||
description: How to use the Nonlinear Autoregressive Exogenous model network in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: recurrent, neural-network, NARX, architecture
|
||||
|
||||
Just like LSTM's, [NARX networks](https://en.wikipedia.org/wiki/Nonlinear_autoregressive_exogenous_model) are very good at timeseries prediction. That is because they use previous inputs and their corresponding output values as the next input to the hidden layer.
|
||||
|
||||

|
||||
|
||||
The constructor looks like this:
|
||||
|
||||
```js
|
||||
var network = new architect.NARX(inputSize, hiddenLayers, outputSize, previousInput, previousOutput);
|
||||
```
|
||||
|
||||
A quick explanation of each argument:
|
||||
|
||||
* `inputSize`: the amount of input nodes
|
||||
* `hiddenLayers`: an array containing hidden layer sizes, e.g. `[10,20,10]`. If only one hidden layer, can be a number (of nodes)
|
||||
* `outputSize`: the amount of output nodes
|
||||
* `previousInput`: the amount of previous inputs you want it to remember
|
||||
* `previousOutput`: the amount of previous outputs you want it to remember
|
||||
|
||||
Example:
|
||||
|
||||
```javascript
|
||||
var narx = new architect.NARX(1, 5, 1, 3, 3);
|
||||
|
||||
// Train the XOR gate (in sequence!)
|
||||
var trainingData = [
|
||||
{ input: [0], output: [0] },
|
||||
{ input: [0], output: [0] },
|
||||
{ input: [0], output: [1] },
|
||||
{ input: [1], output: [0] },
|
||||
{ input: [0], output: [0] },
|
||||
{ input: [0], output: [0] },
|
||||
{ input: [0], output: [1] },
|
||||
];
|
||||
|
||||
narx.train(trainingData, {
|
||||
log: 1,
|
||||
iterations: 3000,
|
||||
error: 0.03,
|
||||
rate: 0.05
|
||||
});
|
||||
```
|
||||
[Run it here](https://jsfiddle.net/wagenaartje/1o7t91yk/2/)
|
||||
|
||||
The NARX network type has 'constant' nodes. These nodes won't affect the weight of their incoming connections and their bias will never change. Please do note that mutation CAN change all of these.
|
||||
19
node_modules/neataptic/mkdocs/templates/docs/builtins/perceptron.md
generated
vendored
Normal file
19
node_modules/neataptic/mkdocs/templates/docs/builtins/perceptron.md
generated
vendored
Normal file
@@ -0,0 +1,19 @@
|
||||
description: How to use the Perceptron network in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: feed-forward, neural-network, perceptron, MLP, architecture
|
||||
|
||||
This architecture allows you to create multilayer perceptrons, also known as feed-forward neural networks. They consist of a sequence of layers, each fully connected to the next one.
|
||||
|
||||

|
||||
|
||||
You have to provide a minimum of 3 layers (input, hidden and output), but you can use as many hidden layers as you wish. This is a `Perceptron` with 2 neurons in the input layer, 3 neurons in the hidden layer, and 1 neuron in the output layer:
|
||||
|
||||
```javascript
|
||||
var myPerceptron = new architect.Perceptron(2,3,1);
|
||||
```
|
||||
|
||||
And this is a deep multilayer perceptron with 2 neurons in the input layer, 4 hidden layers with 10 neurons each, and 1 neuron in the output layer
|
||||
|
||||
```javascript
|
||||
var myPerceptron = new architect.Perceptron(2, 10, 10, 10, 10, 1);
|
||||
```
|
||||
35
node_modules/neataptic/mkdocs/templates/docs/builtins/random.md
generated
vendored
Normal file
35
node_modules/neataptic/mkdocs/templates/docs/builtins/random.md
generated
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
description: How to use the Random model network in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: recurrent, feed-forward, gates, neural-network, random, architecture
|
||||
|
||||
A random network is similar to a liquid network. This network will start of with a given pool of nodes, and will then create random connections between them. This network is really only useful for the initialization of the population for a genetic algorithm.
|
||||
|
||||
```javascript
|
||||
new architect.Random(input_size, hidden_size, output_size, options);
|
||||
```
|
||||
|
||||
* `input_size` : amount of input nodes
|
||||
* `hidden_size` : amount of nodes inbetween input and output
|
||||
* `output_size` : amount of output nodes
|
||||
|
||||
Options:
|
||||
* `connections` : amount of connections (default is `2 * hidden_size`, should always be bigger than `hidden_size`!)
|
||||
* `backconnections` : amount of recurrent connections (default is `0`)
|
||||
* `selfconnections` : amount of selfconnections (default is `0`)
|
||||
* `gates` : amount of gates (default is `0`)
|
||||
|
||||
For example:
|
||||
|
||||
```javascript
|
||||
var network = architect.Random(1, 20, 2, {
|
||||
connections: 40,
|
||||
gates: 4,
|
||||
selfconnections: 4
|
||||
});
|
||||
|
||||
drawGraph(network.graph(1000, 800), '.svg');
|
||||
```
|
||||
|
||||
will produce:
|
||||
|
||||
<img src="https://i.gyazo.com/a6a8076ce043f4892d0a77c6f816f0c0.png" width="100%"/>
|
||||
122
node_modules/neataptic/mkdocs/templates/docs/important/evolve.md
generated
vendored
Normal file
122
node_modules/neataptic/mkdocs/templates/docs/important/evolve.md
generated
vendored
Normal file
@@ -0,0 +1,122 @@
|
||||
description: Documentation of the evolve function, which allows you to evolve neural networks
|
||||
authors: Thomas Wagenaar
|
||||
keywords: neat, neuro-evolution, neataptic, neural-network, javascript
|
||||
|
||||
The evolve function will evolve the network to conform the given training set. If you want to perform neuro-evolution on problems without a training set, check out the [NEAT](../neat.md) wiki page. This function may not always be successful, so always specify a number of iterations for it too maximally run.
|
||||
|
||||
<a href="https://wagenaartje.github.io/neataptic/articles/neuroevolution/">View a whole bunch of neuroevolution algorithms set up with Neataptic here.</a>
|
||||
|
||||
### Constructor
|
||||
Initiating the evolution of your neural network is easy:
|
||||
|
||||
```javascript
|
||||
await myNetwork.evolve(trainingSet, options);
|
||||
```
|
||||
|
||||
Please note that `await` is used as `evolve` is an `async` function. Thus, you
|
||||
need to wrap these statements in an async function.
|
||||
|
||||
#### Training set
|
||||
Where `trainingSet` is your training set. An example is coming up ahead. An example
|
||||
of a training set would be:
|
||||
|
||||
```javascript
|
||||
// XOR training set
|
||||
var trainingSet = [
|
||||
{ input: [0,0], output: [0] },
|
||||
{ input: [0,1], output: [1] },
|
||||
{ input: [1,0], output: [1] },
|
||||
{ input: [1,1], output: [0] }
|
||||
];
|
||||
```
|
||||
|
||||
#### Options
|
||||
There are **a lot** of options, here are the basic options:
|
||||
|
||||
* `cost` - Specify the cost function for the evolution, this tells a genome in the population how well it's performing. Default: _methods.cost.MSE_ (recommended).
|
||||
* `amount`- Set the amount of times to test the trainingset on a genome each generation. Useful for timeseries. Do not use for regular feedfoward problems. Default is _1_.
|
||||
* `growth` - Set the penalty you want to give for large networks. The penalty get's calculated as follows: _penalty = (genome.nodes.length + genome.connectoins.length + genome.gates.length) * growth;_
|
||||
This penalty will get added on top of the error. Your growth should be a very small number, the default value is _0.0001_
|
||||
|
||||
* `iterations` - Set the maximum amount of iterations/generations for the algorithm to run. Always specify this, as the algorithm will not always converge.
|
||||
* `error` - Set the target error. The algorithm will stop once this target error has been reached. The default value is _0.005_.
|
||||
* `log` - If set to _n_, will output every _n_ iterations (_log : 1_ will log every iteration)
|
||||
* `schedule` - You can schedule tasks to happen every _n_ iterations. An example of usage is _schedule : { function: function(){console.log(Date.now)}, iterations: 5}_. This will log the time every 5 iterations. This option allows for complex scheduled tasks during evolution.
|
||||
* `clear` - If set to _true_, will clear the network after every activation. This is useful for evolving recurrent networks, more importantly for timeseries prediction. Default: _false_
|
||||
* `threads` - Specify the amount of threads to use. Default value is the amount of cores in your CPU. Set to _1_ if you are evolving on a small dataset.
|
||||
|
||||
Please note that you can also specify _any_ of the options that are specified on
|
||||
the [neat page](../neat.md).
|
||||
|
||||
An example of options would be:
|
||||
|
||||
```javascript
|
||||
var options = {
|
||||
mutation: methods.mutation.ALL,
|
||||
mutationRate: 0.4,
|
||||
clear: true,
|
||||
cost: methods.cost.MSE,
|
||||
error: 0.03,
|
||||
log: 1,
|
||||
iterations: 1000
|
||||
};
|
||||
```
|
||||
|
||||
If you want to use the default options, you can either pass an empty object or
|
||||
just dismiss the whole second argument:
|
||||
|
||||
```javascript
|
||||
await myNetwork.evolve(trainingSet, {});
|
||||
|
||||
// or
|
||||
|
||||
await myNetwork.evolve(trainingSet);
|
||||
```
|
||||
|
||||
The default value will be used for any option that is not explicitly provided
|
||||
in the options object.
|
||||
|
||||
### Result
|
||||
This function will output an object containing the final error, amount of iterations, time and the evolved network:
|
||||
|
||||
```javascript
|
||||
return results = {
|
||||
error: mse,
|
||||
generations: neat.generation,
|
||||
time: Date.now() - start,
|
||||
evolved: fittest
|
||||
};
|
||||
```
|
||||
|
||||
### Examples
|
||||
|
||||
<details>
|
||||
<summary>XOR</summary>
|
||||
Activates the network. It will activate all the nodes in activation order and produce an output.
|
||||
<pre>
|
||||
async function execute () {
|
||||
var network = new Network(2,1);
|
||||
|
||||
// XOR dataset
|
||||
var trainingSet = [
|
||||
{ input: [0,0], output: [0] },
|
||||
{ input: [0,1], output: [1] },
|
||||
{ input: [1,0], output: [1] },
|
||||
{ input: [1,1], output: [0] }
|
||||
];
|
||||
|
||||
await network.evolve(trainingSet, {
|
||||
mutation: methods.mutation.FFW,
|
||||
equal: true,
|
||||
elitism: 5,
|
||||
mutationRate: 0.5
|
||||
});
|
||||
|
||||
network.activate([0,0]); // 0.2413
|
||||
network.activate([0,1]); // 1.0000
|
||||
network.activate([1,0]); // 0.7663
|
||||
network.activate([1,1]); // -0.008
|
||||
}
|
||||
|
||||
execute();</pre>
|
||||
</details>
|
||||
6
node_modules/neataptic/mkdocs/templates/docs/important/important.md
generated
vendored
Normal file
6
node_modules/neataptic/mkdocs/templates/docs/important/important.md
generated
vendored
Normal file
@@ -0,0 +1,6 @@
|
||||
description: List of important functions in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: train, evolve, neataptic
|
||||
|
||||
* [Train](train.md)
|
||||
* [Evolve](evolve.md)
|
||||
115
node_modules/neataptic/mkdocs/templates/docs/important/train.md
generated
vendored
Normal file
115
node_modules/neataptic/mkdocs/templates/docs/important/train.md
generated
vendored
Normal file
@@ -0,0 +1,115 @@
|
||||
description: Documentation of the train function, used to train neural networks in Neataptic.
|
||||
authors: Thomas Wagenaar
|
||||
keywords: train, backpropagation, neural-network, dropout, momentum, learning rate
|
||||
|
||||
The train method allows you to train your network with given parameters. If this
|
||||
documentation is too complicated, I recommend to check out the
|
||||
[training tutorial](../tutorials/training.md)!
|
||||
|
||||
### Constructor
|
||||
Initiating the training process is similar to initiating the evolution process:
|
||||
|
||||
<pre>
|
||||
myNetwork.train(trainingSet, options)
|
||||
</pre>
|
||||
|
||||
#### Training set
|
||||
|
||||
Where set is an array containing objects in the following way: <code>{ input: [input(s)], output: [output(s)] }</code>. So for example, this is how you would train an XOR:
|
||||
|
||||
<pre>
|
||||
var network = new architect.Perceptron(2,4,1);
|
||||
|
||||
// Train the XOR gate
|
||||
network.train([{ input: [0,0], output: [0] },
|
||||
{ input: [0,1], output: [1] },
|
||||
{ input: [1,0], output: [1] },
|
||||
{ input: [1,1], output: [0] }]);
|
||||
|
||||
network.activate([0,1]); // 0.9824...
|
||||
</pre>
|
||||
|
||||
#### Options
|
||||
|
||||
Options allow you to finetune the training process:
|
||||
|
||||
* `log` - If set to _n_, will output the training status every _n_ iterations (_log : 1_ will log every iteration)
|
||||
* `error` - The target error to reach, once the network falls below this error, the process is stopped. Default: _0.03_
|
||||
* `cost` - The cost function to use. See [cost methods](../methods/cost.md). Default: _methods.cost.MSE_
|
||||
* `rate` - Sets the learning rate of the backpropagation process. Default: _0.3_.
|
||||
* `dropout` - Sets the dropout of the hidden network nodes. Read more about it on the [regularization](../methods/regularization.md) page. Default: _0_.
|
||||
* `shuffle` - When set to _true_, will shuffle the training data every iteration. A good option to use if your network is performing less in cross validation than in the real training set. Default: _false_
|
||||
* `iterations` - Sets the amount of iterations the process will maximally run, even when the target error has not been reached. Default: _NaN_
|
||||
* `schedule` - You can schedule tasks to happen every _n_ iterations. An example of usage is _schedule : { function: function(data){console.log(Date.now, data.error)}, iterations: 5}_. This will log the time and error every 5 iterations. This option allows for complex scheduled tasks during training.
|
||||
* `clear` - If set to _true_, will clear the network after every activation. This is useful for training [LSTM](../builtins/lstm.md)'s, more importantly for timeseries prediction. Default: _false_
|
||||
* `momentum` - Sets the momentum of the weight change. More info [here](https://www.willamette.edu/~gorr/classes/cs449/momrate.html). Default: _0_
|
||||
* `ratePolicy` - Sets the rate policy for your training. This allows your rate to be dynamic, see the [rate policies page](../methods/rate.md). Default: _methods.rate.FIXED()_
|
||||
* `batchSize` - Sets the (mini-) batch size of your training. Default: `1` (online training)
|
||||
|
||||
If you want to use the default options, you can either pass an empty object or
|
||||
just dismiss the whole second argument:
|
||||
|
||||
```javascript
|
||||
myNetwork.evolve(trainingSet, {});
|
||||
|
||||
// or
|
||||
|
||||
myNetwork.evolve(trainingSet);
|
||||
```
|
||||
|
||||
The default value will be used for any option that is not explicitly provided
|
||||
in the options object.
|
||||
|
||||
#### Example
|
||||
|
||||
So the following setup will train until the error of <code>0.0001</code> is reached or if the iterations hit <code>1000</code>. It will log the status every iteration as well. The rate has been lowered to <code>0.2</code>.
|
||||
|
||||
```javascript
|
||||
var network = new architect.Perceptron(2,4,1);
|
||||
|
||||
var trainingSet = [
|
||||
{ input: [0,0], output: [1] },
|
||||
{ input: [0,1], output: [0] },
|
||||
{ input: [1,0], output: [0] },
|
||||
{ input: [1,1], output: [1] }
|
||||
];
|
||||
|
||||
// Train the XNOR gate
|
||||
network.train(trainingSet, {
|
||||
log: 1,
|
||||
iterations: 1000,
|
||||
error: 0.0001,
|
||||
rate: 0.2
|
||||
});
|
||||
```
|
||||
|
||||
#### Cross-validation
|
||||
|
||||
The last option is the **crossValidate** option, which will validate if the network also performs well enough on a non-trained part of the given set. Options:
|
||||
|
||||
* `crossValidate.testSize` - Sets the amount of test cases that should be assigned to cross validation. If set to _0.4_, 40% of the given set will be used for cross validation.
|
||||
* `crossValidate.testError` - Sets the target error of the validation set.
|
||||
|
||||
So an example of cross validation would be:
|
||||
|
||||
```javascript
|
||||
var network = new architect.Perceptron(2,4,1);
|
||||
|
||||
var trainingSet = [
|
||||
{ input: [0,0], output: [1] },
|
||||
{ input: [0,1], output: [0] },
|
||||
{ input: [1,0], output: [0] },
|
||||
{ input: [1,1], output: [1] }
|
||||
];
|
||||
|
||||
// Train the XNOR gate
|
||||
network.train(trainingSet, {
|
||||
crossValidate :
|
||||
{
|
||||
testSize: 0.4,
|
||||
testError: 0.02
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
PS: don't use cross validation for small sets, this is just an example!
|
||||
11
node_modules/neataptic/mkdocs/templates/docs/index.md
generated
vendored
Normal file
11
node_modules/neataptic/mkdocs/templates/docs/index.md
generated
vendored
Normal file
@@ -0,0 +1,11 @@
|
||||
description: Welcome to the documentation of Neataptic!
|
||||
authors: Thomas Wagenaar
|
||||
keywords: machine-learning, neural-network, evolution, backpropagation
|
||||
|
||||
Welcome to the documentation of Neataptic! If you are a rookie with neural networks:
|
||||
check out any of the tutorials on the left to get started. If you want more
|
||||
information about a certain part of Neataptic, it most probably is also in the
|
||||
menu on the left. If it isn't, feel free to let me know by creating an [issue](https://github.com/wagenaartje/neataptic/issues).
|
||||
|
||||
If you want to implement a genetic neural network algorithm, but don't know how,
|
||||
feel free to contact me at [wagenaartje@protonmail.com](mailto:wagenaartje@protonmail.com)!
|
||||
38
node_modules/neataptic/mkdocs/templates/docs/methods/activation.md
generated
vendored
Normal file
38
node_modules/neataptic/mkdocs/templates/docs/methods/activation.md
generated
vendored
Normal file
@@ -0,0 +1,38 @@
|
||||
description: List of activation functions in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: activation function, squash, logistic sigmoid, neuron
|
||||
|
||||
Activation functions determine what activation value neurons should get. Depending on your network's environment, choosing a suitable activation function can have a positive impact on the learning ability of the network.
|
||||
|
||||
### Methods
|
||||
|
||||
Name | Graph | Equation | Derivative
|
||||
---- | ----- | -------- | ----------
|
||||
LOGISTIC | <img src="http://imgur.com/LR7dIMm.png" width="120px"/> | $ f(x) = \frac{1}{1+e^{-x}} $ | $ f'(x) = f(x)(1 - f(x)) $
|
||||
TANH | <img src="http://imgur.com/8lrWuwU.png" width="120px"/> | $ f(x) = tanh(x) = \frac{2}{1+e^{-2x}} - 1 $ | $ f'(x) = 1 - f(x)^2 $
|
||||
RELU | <img src="http://imgur.com/M2FozQu.png" width="120px"/> | $ f(x) = \begin{cases} 0 & \text{if} & x \lt 0 \\\ x & \text{if} & x \ge 0 \end{cases} $ | $ f'(x) = \begin{cases} 0 & \text{if} & x \lt 0 \\\ 1 & \text{if} & x \ge 0 \end{cases} $
|
||||
IDENTITY | <img src="http://imgur.com/3cJ1QTQ.png" width="120px"/> | $ f(x) = x $ | $ f'(x) = 1 $
|
||||
STEP | <img src="http://imgur.com/S5qZbVY.png" width="120px"/> |$ f(x) = \begin{cases} 0 & \text{if} & x \lt 0 \\\ 1 & \text{if} & x \ge 0 \end{cases} $| $ f'(x) = \begin{cases} 0 & \text{if} & x \neq 0 \\\ ? & \text{if} & x = 0 \end{cases} $
|
||||
SOFTSIGN | <img src="http://imgur.com/8bdal1j.png" width="120px"/> | $ f(x) = \frac{x}{1+\left\lvert x \right\rvert} $ | $ f'(x) = \frac{x}{{(1+\left\lvert x \right\rvert)}^2} $
|
||||
SINUSOID | <img src="http://imgur.com/IbxYwL0.png" width="120px"/> | $ f(x) = sin(x) $ | $ f'(x) = cos(x) $
|
||||
GAUSSIAN | <img src="http://imgur.com/aJDCbPI.png" width="120px"/> | $ f(x) = e^{-x^2} $ | $ f'(x) = -2xe^{-x^2} $
|
||||
BENT_IDENTITY | <img src="http://imgur.com/m0RGEDV.png" width="120px"/> | $ f(x) = \frac{\sqrt{x^2+1} - 1}{2} + x$ | $ f'(x) = \frac{ x }{2\sqrt{x^2+1}} + 1 $
|
||||
BIPOLAR | <img src="http://imgur.com/gSiH8hU.png" width="120px"/> | $ f(x) = \begin{cases} -1 & \text{if} & x \le 0 \\\ 1 & \text{if} & x \gt 0 \end{cases} $ | $ f'(x) = 0 $
|
||||
BIPOLAR_SIGMOID | <img src="http://imgur.com/rqXYBaH.png" width="120px"/> | $ f(x) = \frac{2}{1+e^{-x}} - 1$ | $f'(x) = \frac{(1 + f(x))(1 - f(x))}{2} $
|
||||
HARD_TANH | <img src="http://imgur.com/WNqyjdK.png" width="120px"/> | $ f(x) = \text{max}(-1, \text{min}(1, x)) $ | $ f'(x) = \begin{cases} 1 & \text{if} & x \gt -1 & \text{and} & x \lt 1 \\\ 0 & \text{if} & x \le -1 & \text{or} & x \ge 1 \end{cases} $
|
||||
ABSOLUTE<sup>1</sup> | <img src="http://imgur.com/SBs32OI.png" width="120px"/> | $ f(x) = \left\lvert x \right\rvert $ | $ f'(x) = \begin{cases} -1 & \text{if} & x \lt 0 \\\ 1 & \text{if} & x \ge 0 \end{cases} $
|
||||
SELU | <img src="http://i.imgur.com/BCSi7Lu.png" width="120px"/> | $ f(x) = \lambda \begin{cases} x & \text{if} & x \gt 0 \\\ \alpha e^x - \alpha & \text{if} & x \le 0 \end{cases} $ | $ f'(x) = \begin{cases} \lambda & \text{if} & x \gt 0 \\\ \alpha e^x & \text{if} & x \le 0 \end{cases} $
|
||||
INVERSE | <img src="http://imgur.com/n5RiG7N.png" width="120px"/> | $ f(x) = 1 - x $ | $ f'(x) = -1 $
|
||||
|
||||
<sup>1</sup> avoid using this activation function on a node with a selfconnection
|
||||
|
||||
### Usage
|
||||
By default, a neuron uses a [Logistic Sigmoid](http://en.wikipedia.org/wiki/Logistic_function) as its squashing/activation function. You can change that property the following way:
|
||||
|
||||
```javascript
|
||||
var A = new Node();
|
||||
A.squash = methods.activation.<ACTIVATION_FUNCTION>;
|
||||
|
||||
// eg.
|
||||
A.squash = methods.activation.SINUSOID;
|
||||
```
|
||||
40
node_modules/neataptic/mkdocs/templates/docs/methods/cost.md
generated
vendored
Normal file
40
node_modules/neataptic/mkdocs/templates/docs/methods/cost.md
generated
vendored
Normal file
@@ -0,0 +1,40 @@
|
||||
description: List of cost functions in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: cost function, loss function, mse, cross entropy, optimize
|
||||
|
||||
[Cost functions](https://en.wikipedia.org/wiki/Loss_functions_for_classification)
|
||||
play an important role in neural networks. They give neural networks an indication
|
||||
of 'how wrong' they are; a.k.a. how far they are from the desired output. But
|
||||
also in fitness functions, cost functions play an important role.
|
||||
|
||||
### Methods
|
||||
|
||||
At the moment, there are 7 built-in mutation methods (all for networks):
|
||||
|
||||
Name | Function |
|
||||
---- | ------ |
|
||||
[methods.cost.CROSS_ENTROPY](http://neuralnetworksanddeeplearning.com/chap3.html#the_cross-entropy_cost_function) | 
|
||||
[methods.cost.MSE](https://en.wikipedia.org/wiki/Mean_squared_error) | 
|
||||
[methods.cost.BINARY](https://link.springer.com/referenceworkentry/10.1007%2F978-0-387-30164-8_884) | 
|
||||
[methods.cost.MAE](https://en.wikipedia.org/wiki/Mean_absolute_error) | 
|
||||
[methods.cost.MAPE](https://en.wikipedia.org/wiki/Mean_absolute_percentage_error) | 
|
||||
[methods.cost.MSLE](none) | none
|
||||
[methods.cost.HINGE](https://en.wikipedia.org/wiki/Hinge_loss) | 
|
||||
|
||||
### Usage
|
||||
Before experimenting with any of the loss functions, note that not every loss
|
||||
function might 'work' for your network. Some networks have nodes with activation
|
||||
functions that can have negative values; this will create some weird error values
|
||||
with some cost methods. So if you don't know what you're doing: stick to any of
|
||||
the first three cost methods!
|
||||
|
||||
|
||||
```javascript
|
||||
myNetwork.train(trainingData, {
|
||||
log: 1,
|
||||
iterations: 500,
|
||||
error: 0.03,
|
||||
rate: 0.05,
|
||||
cost: methods.cost.METHOD
|
||||
});
|
||||
```
|
||||
14
node_modules/neataptic/mkdocs/templates/docs/methods/gating.md
generated
vendored
Normal file
14
node_modules/neataptic/mkdocs/templates/docs/methods/gating.md
generated
vendored
Normal file
@@ -0,0 +1,14 @@
|
||||
description: List of gating methods in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: gating, recurrent, LSTM, neuron, activation
|
||||
|
||||
Gating is quite the interesting: it makes the weights in networks more dynamic,
|
||||
by adapting them to their gating node. Read more about it [here](https://en.wikipedia.org/wiki/Synaptic_gating).
|
||||
For specific implementation of gating, check out the [Node](../architecture/node.md),
|
||||
[Group](../architecture/group.md) and [Network](../architecture/network.md) wikis!
|
||||
|
||||
There are 3 gating methods:
|
||||
|
||||
* **methods.gating.OUTPUT** every node in the gating group will gate (at least) 1 node in the emitting group and all its connections to the other, receiving group
|
||||
* **methods.gating.INPUT** every node in the gating group will gate (at least) 1 node in the receiving group and all its connections from the other, emitting group
|
||||
* **methods.gating.SELF** every node in the gating group will gate (at least) 1 self connection in the emitting/receiving group
|
||||
10
node_modules/neataptic/mkdocs/templates/docs/methods/methods.md
generated
vendored
Normal file
10
node_modules/neataptic/mkdocs/templates/docs/methods/methods.md
generated
vendored
Normal file
@@ -0,0 +1,10 @@
|
||||
There are **a lot** of different methods for everything in Neataptic. This allows
|
||||
the complete customization of your networks and algorithms. If you feel like any
|
||||
method or function should be added, feel free to create an issue or a pull request.
|
||||
|
||||
* [Activation](activation.md)
|
||||
* [Cost](cost.md)
|
||||
* [Gating](gating.md)
|
||||
* [Mutation](mutation.md)
|
||||
* [Regularization](regularization.md)
|
||||
* [Selection](selection.md)
|
||||
135
node_modules/neataptic/mkdocs/templates/docs/methods/mutation.md
generated
vendored
Normal file
135
node_modules/neataptic/mkdocs/templates/docs/methods/mutation.md
generated
vendored
Normal file
@@ -0,0 +1,135 @@
|
||||
description: List of mutation methods in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: genetic-algorithm, mutation, modify, add, substract, genome, neural-network
|
||||
|
||||
[Mutation](https://en.wikipedia.org/wiki/Mutation_(genetic_algorithm)) is an important aspect of genetic algorithms. Without any mutation, there is low probability of improvement. Mutating will change the bias or weights in neural networks, changing the output of the neural network. It can have a positive, but also a negative effect on the outcome of the neural network. However, one of the [guidelines](https://en.wikipedia.org/wiki/Genetic_algorithm#Selection) of genetic algorithms is too make sure that only the positive effects will be carried on.
|
||||
|
||||
### Methods
|
||||
|
||||
At the moment, there are 7 built-in mutation methods (all for networks):
|
||||
|
||||
Name | Action |
|
||||
---- | ------ |
|
||||
ADD_NODE | Adds a node
|
||||
SUB_NODE | Removes node
|
||||
ADD_CONN | Adds a connection between two nodes
|
||||
SUB_CONN | Removes a connection between two nodes
|
||||
MOD_WEIGHT | Modifies the weight of a connection
|
||||
MOD_BIAS | Modifies the bias of a node
|
||||
MOD_ACTIVATION | Modifies the activation function of a node
|
||||
ADD_SELF_CONN | Adds a self-connection to a node
|
||||
SUB_SELF_CONN | Removes a self-connection from a node
|
||||
ADD_GATE | Makes a node gate a connection
|
||||
SUB_GATE | Removes a gate from a connection
|
||||
ADD_BACK_CONN | Adds a recurrent connection
|
||||
SUB_BACK_CONN | Removes a recurrent connection
|
||||
SWAP_NODES | Swaps the bias and squash function between two nodes
|
||||
|
||||
### Usage
|
||||
All of these mutation functions can be executed on any kind of network:
|
||||
|
||||
```javascript
|
||||
myNetwork.mutate(methods.mutation.<MUTATION_METHOD>);
|
||||
|
||||
// eg.
|
||||
myNetwork.mutate(methods.mutation.ADD_NODE);
|
||||
```
|
||||
|
||||
And some on them on nodes (`MOD_BIAS` and `MOD_ACTIVATION`):
|
||||
|
||||
```javascript
|
||||
myNode.mutate(methods.mutation.<MUTATION_METHOD>);
|
||||
|
||||
// eg.
|
||||
myNode.mutate(methods.mutation.MOD_BIAS);
|
||||
```
|
||||
|
||||
For `network.evolve()` and `neat()` options, specify a list of mutation methods as follows in the options (example):
|
||||
|
||||
```js
|
||||
network.evolve(trainingset, {
|
||||
mutation: [methods.mutation.MOD_BIAS, methods.mutation.ADD_NODE]
|
||||
}
|
||||
```
|
||||
|
||||
You can also specify groups of methods:
|
||||
|
||||
```js
|
||||
network.evolve(trainingset, {
|
||||
mutation: methods.mutation.ALL // all mutation methods
|
||||
}
|
||||
|
||||
network.evolve(trainingset, {
|
||||
mutation: methods.mutation.FFW// all feedforward mutation methods
|
||||
}
|
||||
```
|
||||
|
||||
# Config
|
||||
Some methods are configurable! You can change these config values as follows:
|
||||
|
||||
```js
|
||||
option = value;
|
||||
|
||||
// eg.
|
||||
methods.mutation.MOD_ACTIVATION.mutateOutput = false;
|
||||
```
|
||||
|
||||
Or you can edit the `methods/mutation.js` file to change the default values.
|
||||
|
||||
‌
|
||||
|
||||
```js
|
||||
methods.mutation.SUB_NODE.keep_gates // default: true
|
||||
```
|
||||
When removing a node, you remove the connections and initialize new ones. Setting this option to true will make sure if the removed connections were gated, so will the new ones be.
|
||||
|
||||
‌
|
||||
|
||||
```js
|
||||
methods.mutation.MOD_WEIGHT.min // default: -1
|
||||
methods.mutation.MOD_WEIGHT.max // default: 1
|
||||
```
|
||||
Sets the upper and lower bounds of the modification of connection weights.
|
||||
|
||||
‌
|
||||
|
||||
```js
|
||||
methods.mutation.MOD_BIAS.min // default: -1
|
||||
methods.mutation.MOD_BIAS.max // default: 1
|
||||
```
|
||||
Sets the upper and lower bounds of the modification of neuron biases.
|
||||
|
||||
‌
|
||||
|
||||
```js
|
||||
methods.mutation.MOD_ACTIVATION.mutateOutput // default: true
|
||||
methods.mutation.SWAP_NODES.mutateOutput // default: true
|
||||
```
|
||||
Disable this option if you want the have the activation function of the output neurons unchanged. Useful if you want to keep the output of your neural network normalized.
|
||||
|
||||
‌
|
||||
|
||||
```js
|
||||
methods.mutation.MOD_ACTIVATION.allowed
|
||||
|
||||
// default:
|
||||
[
|
||||
activation.LOGISTIC,
|
||||
activation.TANH,
|
||||
activation.RELU,
|
||||
activation.IDENTITY,
|
||||
activation.STEP,
|
||||
activation.SOFTSIGN,
|
||||
activation.SINUSOID,
|
||||
activation.GAUSSIAN,
|
||||
activation.BENT_IDENTITY,
|
||||
activation.BIPOLAR,
|
||||
activation.BIPOLAR_SIGMOID,
|
||||
activation.HARD_TANH,
|
||||
activation.ABSOLUTE
|
||||
]
|
||||
```
|
||||
|
||||
This option allows you to specify which [activation functions](activation.md) you want to allow in your neural network.
|
||||
|
||||
‌
|
||||
76
node_modules/neataptic/mkdocs/templates/docs/methods/rate.md
generated
vendored
Normal file
76
node_modules/neataptic/mkdocs/templates/docs/methods/rate.md
generated
vendored
Normal file
@@ -0,0 +1,76 @@
|
||||
description: A list of rate policies that can be used during the training of neural networks.
|
||||
authors: Thomas Wagenaar
|
||||
keywords: learning rate, policy, exponential, step, neural-network
|
||||
|
||||
Rate policies allow the rate to be dynamic during the training of neural networks.
|
||||
A few rate policies have been built-in, but it is very easy to create your own
|
||||
as well. A detailed description of each rate policy is given below.
|
||||
|
||||
You can enable a rate policy during training like this:
|
||||
|
||||
```javascript
|
||||
network.train(trainingSet, {
|
||||
rate: 0.3,
|
||||
ratePolicy: methods.rate.METHOD(options),
|
||||
});
|
||||
```
|
||||
|
||||
#### methods.rate.FIXED
|
||||
The default rate policy. Using this policy will make your rate static (it won't
|
||||
change). You do not have to specify this rate policy during training per se.
|
||||
|
||||
#### methods.rate.STEP
|
||||
The rate will 'step down' every `n` iterations.
|
||||
|
||||
|
||||
|
||||
The main usage of this policy is:
|
||||
|
||||
```javascript
|
||||
methods.rate.STEP(gamma, stepSize)
|
||||
|
||||
// default gamma: 0.9
|
||||
// default stepSize: 100
|
||||
```
|
||||
|
||||
A gamma of `0.9` means that every `stepSize` iterations, your current rate will
|
||||
be reduced by 10%.
|
||||
|
||||
#### methods.rate.EXP
|
||||
The rate will exponentially decrease.
|
||||
|
||||

|
||||
|
||||
The main usage of this policy is:
|
||||
|
||||
```javascript
|
||||
methods.rate.EXP(gamma)
|
||||
|
||||
// default gamma: 0.999
|
||||
```
|
||||
|
||||
The rate at a certain iteration is calculated as:
|
||||
|
||||
```javascript
|
||||
rate = baseRate * Math.pow(gamma, iteration)
|
||||
```
|
||||
|
||||
So a gamma of `0.999` will decrease the current rate by 0.1% every iteration
|
||||
|
||||
#### methods.rate.INV
|
||||
|
||||
|
||||
The main usage of this policy is:
|
||||
|
||||
```javascript
|
||||
methods.rate.INV(gamma, power)
|
||||
|
||||
// default gamma: 0.001
|
||||
// default power: 2
|
||||
```
|
||||
|
||||
The rate at a certain iteration is calculated as:
|
||||
|
||||
```javascript
|
||||
rate = baseRate * Math.pow(1 + gamma * iteration, -power)
|
||||
```
|
||||
54
node_modules/neataptic/mkdocs/templates/docs/methods/regularization.md
generated
vendored
Normal file
54
node_modules/neataptic/mkdocs/templates/docs/methods/regularization.md
generated
vendored
Normal file
@@ -0,0 +1,54 @@
|
||||
description: List of regularization methods in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: regularization, dropout, neural-network, training, backpropagation, momentum
|
||||
|
||||
Regularization helps to keep weights and/or biases small in your network. Some
|
||||
regularization methods also make sure that you are not overfitting your data.
|
||||
|
||||
### Dropout
|
||||
Enabling dropout will randomly set the activation of a neuron in a network to `0`
|
||||
with a given probability.
|
||||
|
||||
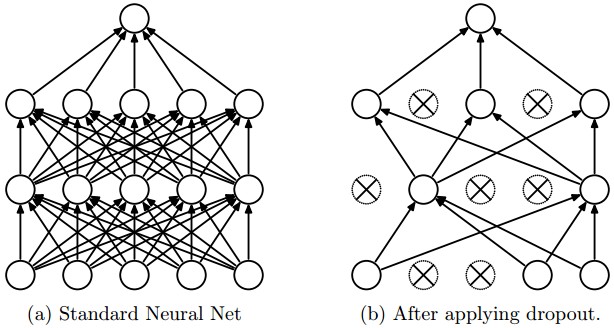
|
||||
|
||||
Only use dropout when you are working with large datasets that may show some noise.
|
||||
Dropout is a method that prevents overfitting, but it shouldn't work on datasets
|
||||
like XOR or SINUS, as they don't have any noise. Dropout can only be used during
|
||||
training:
|
||||
|
||||
```javascript
|
||||
myNetwork.train(myTrainingSet, {
|
||||
error: 0.03,
|
||||
iterations: 1000,
|
||||
rate: 0.3,
|
||||
dropout: 0.4 // if you're not sure, use 0.5
|
||||
});
|
||||
```
|
||||
|
||||
Setting the dropout to `0.4` means that 40% of the neurons will be dropped out
|
||||
every training iteration. Please note that Neataptic has no layered network
|
||||
architecture, so dropout applies to the complete hidden area.
|
||||
|
||||
### Momentum
|
||||
Momentum simply adds a fraction m of the previous weight update to the current one.
|
||||
When the gradient keeps pointing in the same direction, this will increase the size
|
||||
of the steps taken towards the minimum. It is therefore often necessary to reduce
|
||||
the global learning rate µ when using a lot of momentum (m close to 1).
|
||||
If you combine a high learning rate with a lot of momentum, you will rush past the
|
||||
minimum with huge steps! Read more about it [here](https://www.willamette.edu/~gorr/classes/cs449/momrate.html).
|
||||
|
||||

|
||||
|
||||
you can use this option during training:
|
||||
|
||||
```javascript
|
||||
myNetwork.train(myTrainingSet, {
|
||||
error: 0.03,
|
||||
iterations: 1000,
|
||||
rate: 0.3,
|
||||
momentum: 0.9
|
||||
});
|
||||
```
|
||||
|
||||
Setting the momentum to `0.9` will mean that 90% of the previous weight change
|
||||
will be included in the current weight change.
|
||||
78
node_modules/neataptic/mkdocs/templates/docs/methods/selection.md
generated
vendored
Normal file
78
node_modules/neataptic/mkdocs/templates/docs/methods/selection.md
generated
vendored
Normal file
@@ -0,0 +1,78 @@
|
||||
description: List of selection methods in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: genetic-algorithm, fitness, elitism, selection
|
||||
|
||||
[Selection](https://en.wikipedia.org/wiki/Selection_(genetic_algorithm)) is the
|
||||
way in which a genetic algorithm decides which neural networks will be parents
|
||||
for the new generation. There are a couple of selection methods, however only a
|
||||
few have been integrated until now.
|
||||
|
||||
At the moment, there are 3 built-in selection methods:
|
||||
|
||||
Name |
|
||||
---- |
|
||||
selection.POWER |
|
||||
selection.FITNESS_PROPORTIONATE |
|
||||
selection.TOURNAMENT |
|
||||
|
||||
_A description on how each of these work is given below_
|
||||
|
||||
### Usage
|
||||
You can specify your selection method while calling the `evolve()` function on a
|
||||
network or when constructing a new instance of the `NEAT` algorithm:
|
||||
|
||||
```javascript
|
||||
var myNetwork = new architect.Perceptron(1,1,1);
|
||||
var myTrainingSet = [{ input:[0], output:[1]}, { input:[1], output:[0]}];
|
||||
|
||||
myNetwork.evolve(myTrainingSet, {
|
||||
generations: 10,
|
||||
selection: methods.selection.POWER // eg.
|
||||
});
|
||||
```
|
||||
|
||||
Next to selection methods, `elitism` is also built in the `NEAT` constructor.
|
||||
[Elitism](https://en.wikipedia.org/wiki/Genetic_algorithm#Elitism) allows a
|
||||
genetic algorithm to pass on `n` neural networks with the highest fitness from
|
||||
the previous generation to the new generation, without any crossover steps in
|
||||
between. At the moment, elitism is only possible inside a `Neat` object. They
|
||||
can be passed on as follows:
|
||||
|
||||
```javascript
|
||||
var evolution = new Neat({
|
||||
selection: methods.selection.FITNESS_PROPORTIONATE,
|
||||
elitism: 5 // amount of neural networks to keep from generation to generation
|
||||
});
|
||||
```
|
||||
|
||||
#### methods.selection.POWER
|
||||
When using this selection method, a random decimal value between 0 and 1 will
|
||||
be generated. E.g. `0.5`, then this value will get an exponential value, the
|
||||
default power is `4`. So `0.5**4 = 0.0625`. This will be converted into an index
|
||||
for the array of the current population, which is sorted from fittest to worst.
|
||||
|
||||
**Config:**
|
||||
|
||||
* _methods.selection.POWER.power_ : default is `4`. Increasing this value will
|
||||
increase the chance fitter genomes are chosen.
|
||||
|
||||
#### methods.selection.FITNESS_PROPORTIONATE
|
||||
This selection method will select genomes with a probability proportionate to their fitness:
|
||||
|
||||

|
||||
|
||||
Read more about roulette selection [here](https://en.wikipedia.org/wiki/Fitness_proportionate_selection).
|
||||
|
||||
#### methods.selection.TOURNAMENT
|
||||
This selection method will select a group of genomes from the population randomly,
|
||||
sort them by score, and choose the fittest individual with probability `p`, the
|
||||
second fittest with probability `p*(1-p)`, the third fittest with probability
|
||||
`p*((1-p)^2)`and so on. Read more [here](https://en.wikipedia.org/wiki/Tournament_selection).
|
||||
|
||||
**Config:**
|
||||
|
||||
* _methods.selection.TOURNAMENT.size_ : default is `5`. Must always be lower than
|
||||
the population size. A higher value will result in a population that has more
|
||||
equal, but fitter, parents.
|
||||
* _methods.selection.TOURNAMENT.probability_ : default is `0.5`. See the
|
||||
explanation above on how it is implemented.
|
||||
109
node_modules/neataptic/mkdocs/templates/docs/tutorials/evolution.md
generated
vendored
Normal file
109
node_modules/neataptic/mkdocs/templates/docs/tutorials/evolution.md
generated
vendored
Normal file
@@ -0,0 +1,109 @@
|
||||
description: A simple tutorial on how to get started on evolving neural networks with Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: evolution, machine-learning, neural-network, neuro-evolution, neat
|
||||
|
||||
Neuro-evolution is something that is fairly underused in the machine learning
|
||||
community. It is quite interesting to see new architectures develop for
|
||||
complicated problems. In this guide I will tell you how to set up a simple
|
||||
supervised neuro-evolution process. If you want to do an unsupervised
|
||||
neuro-evolution process, head over to the [NEAT](../neat.md) page.
|
||||
|
||||
### The training set
|
||||
You always have to supply a training set for supervised learning. First of all,
|
||||
you should normalize your data. That means you have to convert all your input and
|
||||
output data to values within a range of `0` to `1`. If you are unsure how to do
|
||||
this, visit the [Normalization](normalization.md) tutorial. Each training sample
|
||||
in your training set should be an object that looks as follows:
|
||||
|
||||
```javascript
|
||||
{ input: [], output: [] }
|
||||
```
|
||||
|
||||
So an example of a training set would be (XOR):
|
||||
|
||||
```javascript
|
||||
var myTrainingSet = [
|
||||
{ input: [0,0], output: [0] },
|
||||
{ input: [0,1], output: [1] },
|
||||
{ input: [1,0], output: [1] },
|
||||
{ input: [1,1], output: [0] }
|
||||
];
|
||||
```
|
||||
|
||||
### The network architecture
|
||||
You can start off with _any_ architecture. You can even use the evolution process
|
||||
to optimize already trained networks. However, I advise you to start with an empty
|
||||
network, as originally described in the [NEAT](http://nn.cs.utexas.edu/downloads/papers/stanley.ec02.pdf)
|
||||
paper. The constructor of an empty network is as follows:
|
||||
|
||||
```javascript
|
||||
var myNetwork = new Network(inputSize, outputSize);
|
||||
```
|
||||
|
||||
So for the training set I made above, the network can be constructed as follows:
|
||||
|
||||
```javascript
|
||||
var myNetwork = new Network(2, 1); // 2 inputs, 1 output
|
||||
```
|
||||
|
||||
Now we have our network. We don't have to tinker around anymore; the evolution
|
||||
process will do that _for_ us.
|
||||
|
||||
### Evolving the network
|
||||
Be warned: there are _a lot_ of options involved in the evolution of a process.
|
||||
It's a matter of trial and error before you reach options that work really well.
|
||||
Please note that most options are optional, as default values have been configured.
|
||||
|
||||
Please note that the `evolve` function is an `async` function, so you need to wrap
|
||||
it in an async function to call `await`.
|
||||
|
||||
The evolve function is as follows:
|
||||
|
||||
```javascript
|
||||
yourNetwork.evolve(yourData, yourOptions);
|
||||
```
|
||||
|
||||
Check out the evolution options [here](../architecture/network.md) and [here](../neat.md). I'm going to use the following options to evolve the network:
|
||||
|
||||
* `mutation: methods.mutation.FFW` - I want to solve a feed forward problem, so I supply all feed forward mutation methods. More info [here](../methods/mutation.md).
|
||||
* `equal: true` - During the crossover process, parent networks will be equal. This allows the spawning of new network architectures more easily.
|
||||
* `popsize: 100` - The default population size is 50, but 100 worked better for me.
|
||||
* `elitism: 10` - I want to keep the fittest 10% of the population to the next generation without breeding them.
|
||||
* `log: 10` - I want to log the status every 10 iterations.
|
||||
* `error: 0.03` - I want the evolution process when the error is below 0.03;
|
||||
* `iterations: 1000` - I want the evolution process to stop after 1000 iterations if the target error hasn't been reached yet.
|
||||
* `mutationRate: 0.5` - I want to increase the mutation rate to surpass possible local optima.
|
||||
|
||||
So let's put it all together:
|
||||
|
||||
```javascript
|
||||
await myNetwork.evolve(myTrainingSet, {
|
||||
mutation: methods.mutation.FFW,
|
||||
equal: true,
|
||||
popsize: 100,
|
||||
elitism: 10,
|
||||
log: 10,
|
||||
error: 0.03,
|
||||
iterations: 1000,
|
||||
mutationRate: 0.5
|
||||
});
|
||||
|
||||
// results: {error: 0.0009000000000000001, generations: 255, time: 1078}
|
||||
// please note that there is a hard local optima that has to be beaten
|
||||
```
|
||||
|
||||
Now let us check if it _actually_ works:
|
||||
|
||||
```javascript
|
||||
myNetwork.activate([0,0]); // [0]
|
||||
myNetwork.activate([0,1]); // [1]
|
||||
myNetwork.activate([1,0]); // [1]
|
||||
myNetwork.activate([1,1]); // [0]
|
||||
```
|
||||
|
||||
Notice how precise the results are. That is because the evolution process makes
|
||||
full use of the diverse activation functions. It actually uses the [Activation.STEP](../methods/activation.md)
|
||||
function to get a binary `0` and `1` output.
|
||||
|
||||
### Help
|
||||
If you need more help, feel free to create an issue [here](https://github.com/wagenaartje/neataptic/issues)!
|
||||
108
node_modules/neataptic/mkdocs/templates/docs/tutorials/normalization.md
generated
vendored
Normal file
108
node_modules/neataptic/mkdocs/templates/docs/tutorials/normalization.md
generated
vendored
Normal file
@@ -0,0 +1,108 @@
|
||||
description: A tutorial on how to standardize/normalize your data for neural networks
|
||||
authors: Thomas Wagenaar
|
||||
keywords: normalize, 0, 1, standardize, input, output, neural-network
|
||||
|
||||
Although Neataptic networks accepts non-normalized values as input, normalizing your input makes your network converge faster. I see a lot of questions where people ask how to normalize their data correctly, so I decided to make a guide.
|
||||
|
||||
### Example data
|
||||
You have gathered this information, now you want to use it to train/activate a neural network:
|
||||
|
||||
```javascript
|
||||
{ stock: 933, sold: 352, price: 0.95, category: 'drinks', id: 40 }
|
||||
{ stock: 154, sold: 103, price: 5.20, category: 'foods', id: 67 }
|
||||
{ stock: 23, sold: 5, price: 121.30, category: 'electronics', id: 150 }
|
||||
```
|
||||
|
||||
So some information on the above data:
|
||||
* `stock`: the amount of this item in stock
|
||||
* `sold`: the amount of this item sold ( in the last month )
|
||||
* `price`: the price of this item
|
||||
* `category`: the type of product
|
||||
* `id`: the id of the product
|
||||
|
||||
### Normalize
|
||||
So we want to represent each of these inputs as a number between `0` and `1`, however, we can not change the relativity between the values. So we need to treat each different input the same (`stock` gets treated the same for every item for example).
|
||||
|
||||
We have two types of values in our input data: numerical values and categorical values. These should always be treated differently.
|
||||
|
||||
#### Numerical values
|
||||
|
||||
Numerical values are values where the distance between two values matters. For example, `price: 0.95` is twice as small as `price: 1.90`. But not all integers/decimals are numerical values. Id's are often represented with numbers, but there is no relation between `id: 4` and `id: 8` . So these should be treated as categorical values.
|
||||
|
||||
Normalizing numerical values is quite easy, we just need to determine a maximum value we divide a certain input with. For example, we have the following data:
|
||||
|
||||
```javascript
|
||||
stock: 933
|
||||
stock: 154
|
||||
stock: 23
|
||||
```
|
||||
|
||||
We need to choose a value which is `>= 933` with which we divide all the `stock` values. We could choose `933`, but what if we get new data, where the `stock` value is higher than `933`? Then we have to renormalize all the data and retrain the network.
|
||||
|
||||
So we need to choose a value that is `>=933`, but also `>= future values` and it shouldn't be a too big number. We could make the assumption that the `stock` will never get larger than `2000`, so we choose `2000` as our maximum value. We now normalize our data with this maximum value:
|
||||
|
||||
```javascript
|
||||
// Normalize the data with a maximum value (=2000)
|
||||
stock: 933 -> 933/2000 -> 0.4665
|
||||
stock: 154 -> 154/2000 -> 0.077
|
||||
stock: 23 -> 23/2000 -> 0.0115
|
||||
```
|
||||
|
||||
#### Categorical data
|
||||
Categorical data shows no relation between different categories. So each category should be treated as a seperate input, this is called [one-hot encoding](https://en.wikipedia.org/wiki/One-hot). Basically, you create a seperate input for each category. You set all the inputs to `0`, except for the input which matches the sample category. This is one-hot encoding for our above training data:
|
||||
|
||||
<table class="table table-striped">
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Sample</th>
|
||||
<th>Drinks</th>
|
||||
<th>Foods</th>
|
||||
<th>Electronics</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>1</td>
|
||||
<td>1</td>
|
||||
<td>0</td>
|
||||
<td>0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>2</td>
|
||||
<td>0</td>
|
||||
<td>1</td>
|
||||
<td>0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>3</td>
|
||||
<td>0</td>
|
||||
<td>0</td>
|
||||
<td>1</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
But this also allows the addition of new categories over time: you just a need input. It has no effect on the performances of the network on the past training data as when the new category is set to `0`, it has no effect (`weight * 0 = 0`).
|
||||
|
||||
### Normalized data
|
||||
So applying what I have explained above creates our normalized data, note that the relativity between inputs has not been changed. Also note that some values may be rounded in the table below.
|
||||
|
||||
```javascript
|
||||
{ stock: 0.4665, sold: 0.352, price: 0.00317, drinks: 1, foods: 0, electronics: 0, id40: 1, id67: 0, id150: 0 }
|
||||
{ stock: 0.077, sold: 0.103, price: 0.01733, drinks: 0, foods: 1, electronics: 0, id40: 0, id67: 1, id150: 0 }
|
||||
{ stock: 0.0115, sold: 0.005, price: 0.40433, drinks: 0, foods: 0, electronics: 1, id40: 0, id67: 0, id150: 1 }
|
||||
```
|
||||
|
||||
Max values:
|
||||
|
||||
* `stock`: 2000
|
||||
* `sold`: 1000
|
||||
* `price` : 300
|
||||
|
||||
Please note, that these inputs should be provided in arrays for neural networks in Neataptic:
|
||||
|
||||
```javascript
|
||||
[ 0.4665, 0.352, 0.00317, 1, 0, 0, 1, 0, 0 ]
|
||||
[ 0.77, 0.103, 0.01733, 0, 1, 0, 0, 1, 0 ]
|
||||
[ 0.0115, 0.005, 0.40433, 0, 0, 1, 0, 0, 1 ]
|
||||
```
|
||||
81
node_modules/neataptic/mkdocs/templates/docs/tutorials/training.md
generated
vendored
Normal file
81
node_modules/neataptic/mkdocs/templates/docs/tutorials/training.md
generated
vendored
Normal file
@@ -0,0 +1,81 @@
|
||||
description: A simple tutorial on how to get started on training neural networks with Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: training, machine-learning, neural-network, backpropagation
|
||||
|
||||
Training your network is not that hard to do - it's the preparation that is harder.
|
||||
|
||||
### The training set
|
||||
First of all, you should normalize your data. That means you have to convert all your input and output data to values within a range of `0` to `1`. If you are unsure how to do this, visit the [Normalization](normalization.md) page. Each training sample in your training set should be an object that looks as follows:
|
||||
|
||||
```javascript
|
||||
{ input: [], output: [] }
|
||||
```
|
||||
|
||||
So an example of a training set would be (XOR):
|
||||
|
||||
```javascript
|
||||
var myTrainingSet = [
|
||||
{ input: [0,0], output: [0] },
|
||||
{ input: [0,1], output: [1] },
|
||||
{ input: [1,0], output: [1] },
|
||||
{ input: [1,1], output: [0] }
|
||||
];
|
||||
```
|
||||
|
||||
### The network architecture
|
||||
There is no fixed rule of thumb for choosing your network architecture. Adding more layers makes your neural network recognize more abstract relationships, although it requires more computation. Any function can be mapped with just one (big) hidden layer, but I do not advise this. I advise to use any of the following architectures if you're a starter:
|
||||
|
||||
* [Perceptron](../builtins/perceptron.md) - a fully connected feed forward network
|
||||
* [LSTM](../builtins/lstm.md) - a recurrent network that can recognize patterns over very long time lags between inputs.
|
||||
* [NARX](../builtins/narx.md) - a recurrent network that remembers previous inputs and outputs
|
||||
|
||||
But for most problems, a perceptron is sufficient. Now you only have to determine the size and amount of the network layers. I advise you to take a look at this [StackExchange question](https://stats.stackexchange.com/questions/181/how-to-choose-the-number-of-hidden-layers-and-nodes-in-a-feedforward-neural-netw) for more help on deciding the hidden size.
|
||||
|
||||
For the training set I provided above (XOR), there are only 2 inputs and one output. I use the rule of thumb: `input size + output size = hidden size`. So the creation of my network would like this:
|
||||
|
||||
```javascript
|
||||
myNetwork = architect.Perceptron(2, 3, 1);
|
||||
```
|
||||
|
||||
### Training the network
|
||||
Finally: we're going to train the network. The function for training your network is very straight-forward:
|
||||
|
||||
```javascript
|
||||
yourNetwork.train(yourData, yourOptions);
|
||||
```
|
||||
|
||||
There are _a lot_ of options. I won't go over all of them here, but you can check out the [Network wiki](../architecture/network.md) for all the options.
|
||||
|
||||
I'm going to use the following options:
|
||||
|
||||
* `log: 10` - I want to log the status every 10 iterations
|
||||
* `error: 0.03` - I want the training to stop if the error is below 0.03
|
||||
* `iterations: 1000` - I want the training to stop if the error of 0.03 hasn't been reached after 1000 iterations
|
||||
* `rate: 0.3` - I want a learning rate of 0.3
|
||||
|
||||
So let's put it all together:
|
||||
|
||||
```javascript
|
||||
myNetwork.train(myTrainingSet, {
|
||||
log: 10,
|
||||
error: 0.03,
|
||||
iterations: 1000,
|
||||
rate: 0.3
|
||||
});
|
||||
|
||||
// result: {error: 0.02955628620843985, iterations: 566, time: 31}
|
||||
```
|
||||
|
||||
Now let us check if it _actually_ works:
|
||||
|
||||
```javascript
|
||||
myNetwork.activate([0,0]); // [0.1257225731473885]
|
||||
myNetwork.activate([0,1]); // [0.9371910625522613]
|
||||
myNetwork.activate([1,0]); // [0.7770757408042104]
|
||||
myNetwork.activate([1,1]); // [0.1639697315652196]
|
||||
```
|
||||
|
||||
And it works! If you want it to be more precise, lower the target error.
|
||||
|
||||
### Help
|
||||
If you need more help, feel free to create an issue [here](https://github.com/wagenaartje/neataptic/issues)!
|
||||
11
node_modules/neataptic/mkdocs/templates/docs/tutorials/tutorials.md
generated
vendored
Normal file
11
node_modules/neataptic/mkdocs/templates/docs/tutorials/tutorials.md
generated
vendored
Normal file
@@ -0,0 +1,11 @@
|
||||
In order to get you started on Neataptic, a few tutorials have been written that
|
||||
give a basic overview on how to create, train and evolve your networks. It is
|
||||
recommended to read all of them before you start digging in your own project.
|
||||
|
||||
* [Training](training.md)
|
||||
* [Evolution](evolution.md)
|
||||
* [Normalization](normalization.md)
|
||||
* [Visualization](visualization.md)
|
||||
|
||||
If you have any questions, feel free to create an issue [here](https://github.com/wagenaartje/neataptic/issues).
|
||||
If you feel like anything is missing, feel free to create a pull request!
|
||||
82
node_modules/neataptic/mkdocs/templates/docs/tutorials/visualization.md
generated
vendored
Normal file
82
node_modules/neataptic/mkdocs/templates/docs/tutorials/visualization.md
generated
vendored
Normal file
@@ -0,0 +1,82 @@
|
||||
description: A simple tutorial on how to visualize neural-networks in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: graph, model, neural-network, visualize, nodes, connections
|
||||
|
||||
This is a step-by-step tutorial aimed to teach you how to create and visualise neural networks using Neataptic.
|
||||
|
||||
**Step 1**
|
||||
Create a javascript file. Name it anything you want. But make sure to start it off with the following:
|
||||
|
||||
```javascript
|
||||
var Node = neataptic.Node;
|
||||
var Neat = neataptic.Neat;
|
||||
var Network = neataptic.Network;
|
||||
var Methods = neataptic.Methods;
|
||||
var Architect = neataptic.Architect;
|
||||
```
|
||||
|
||||
This makes the whole developing a whole lot easier
|
||||
|
||||
**Step 2**
|
||||
Create a html file. Copy and paste this template if you want:
|
||||
|
||||
```html
|
||||
<html>
|
||||
<head>
|
||||
<script src="http://d3js.org/d3.v3.min.js"></script>
|
||||
<script src="http://marvl.infotech.monash.edu/webcola/cola.v3.min.js"></script>
|
||||
|
||||
<script src="https://rawgit.com/wagenaartje/neataptic/master/dist/neataptic.js"></script>
|
||||
<script src="https://rawgit.com/wagenaartje/neataptic/master/graph/graph.js"></script>
|
||||
<link rel="stylesheet" type="text/css" href="https://rawgit.com/wagenaartje/neataptic/master/graph/graph.css">
|
||||
</head>
|
||||
<body>
|
||||
<div class="container">
|
||||
<div class="row">
|
||||
<svg class="draw" width="1000px" height="1000px"/>
|
||||
</div>
|
||||
</div>
|
||||
<script src="yourscript.js"></script>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
**Step 3** Create a network. You can do that in any of the following ways:
|
||||
|
||||
```javascript
|
||||
var network = architect.Random(2, 20, 2, 2);
|
||||
```
|
||||
|
||||
```javascript
|
||||
var network = architect.Perceptron(2, 10, 10, 2);
|
||||
```
|
||||
|
||||
Or if you want to be more advanced, construct your own:
|
||||
```javascript
|
||||
var A = new Node();
|
||||
var B = new Node();
|
||||
var C = new Node();
|
||||
var D = new Node();
|
||||
var E = new Node();
|
||||
var F = new Node();
|
||||
|
||||
var nodes = [A, B, C, D, E, F];
|
||||
|
||||
for(var i = 0; i < nodes.length-1; i++){
|
||||
node = nodes[i];
|
||||
for(var j = 0; j < 2; j++){
|
||||
var connectTo = nodes[Math.floor(Math.random() * (nodes.length - i) + i)];
|
||||
node.connect(connectTo);
|
||||
}
|
||||
}
|
||||
|
||||
var network = architect.Construct(nodes);
|
||||
```
|
||||
|
||||
**Step 4** Retrieve data and draw a graph
|
||||
```javascript
|
||||
drawGraph(network.graph(1000, 1000), '.draw');
|
||||
```
|
||||
|
||||
See a working example [here](https://jsfiddle.net/ch8s9d3e/30/)!
|
||||
See more info on graphs [here](https://github.com/wagenaartje/neataptic/tree/master/graph)!
|
||||
0
node_modules/neataptic/mkdocs/templates/index.md
generated
vendored
Normal file
0
node_modules/neataptic/mkdocs/templates/index.md
generated
vendored
Normal file
Reference in New Issue
Block a user