整理桌面
This commit is contained in:
11
node_modules/neataptic/mkdocs/templates/docs/builtins/builtins.md
generated
vendored
Normal file
11
node_modules/neataptic/mkdocs/templates/docs/builtins/builtins.md
generated
vendored
Normal file
@@ -0,0 +1,11 @@
|
||||
If you are unfamiliar with building networks layer by layer, you can use the
|
||||
preconfigured networks. These networks will also be built layer by layer behind
|
||||
the screens, but for the user they are all a simple one line function. At this
|
||||
moment, Neataptic offers 6 preconfigured networks.
|
||||
|
||||
* [GRU](gru.md)
|
||||
* [Hopfield](hopfield.md)
|
||||
* [LSTM](lstm.md)
|
||||
* [NARX](narx.md)
|
||||
* [Perceptron](perceptron.md)
|
||||
* [Random](random.md)
|
||||
49
node_modules/neataptic/mkdocs/templates/docs/builtins/gru.md
generated
vendored
Normal file
49
node_modules/neataptic/mkdocs/templates/docs/builtins/gru.md
generated
vendored
Normal file
@@ -0,0 +1,49 @@
|
||||
description: How to use the Gated Recurrent Unit network in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: recurrent, neural-network, GRU, architecture
|
||||
|
||||
> Please be warned: GRU is still being tested, it might not always work for your dataset.
|
||||
|
||||
The Gated Recurrent Unit network is very similar to the LSTM network. GRU networks have óne gate less and no selfconnections. Similarly to LSTM's, GRU's are well-suited to classify, process and predict time series when there are very long time lags of unknown size between important events.
|
||||
|
||||
<img src="http://colah.github.io/posts/2015-08-Understanding-LSTMs/img/LSTM3-var-GRU.png" width="100%"/>
|
||||
|
||||
To use this architecture you have to set at least one input node, one gated recurrent unit assembly, and an output node. The gated recurrent unit assembly consists of seven nodes: input, update gate, inverse update gate, reset gate, memorycell, output and previous output memory.
|
||||
|
||||
```javascript
|
||||
var myLSTM = new architect.GRU(2,6,1);
|
||||
```
|
||||
|
||||
Also you can set many layers of gated recurrent units:
|
||||
|
||||
```javascript
|
||||
var myLSTM = new architect.GRU(2, 4, 4, 4, 1);
|
||||
```
|
||||
|
||||
The above network has 3 hidden layers, with 4 GRU assemblies each. It has two inputs and óne output.
|
||||
|
||||
While training sequences or timeseries prediction to a GRU, make sure you set the `clear` option to true while training. Additionally, through trial and error, I have discovered that using a lower rate than normal works best for GRU networks (e.g. `0.1` instead of `0.3`).
|
||||
|
||||
This is an example of training the sequence XOR gate to a a GRU network:
|
||||
|
||||
```js
|
||||
var trainingSet = [
|
||||
{ input: [0], output: [0]},
|
||||
{ input: [1], output: [1]},
|
||||
{ input: [1], output: [0]},
|
||||
{ input: [0], output: [1]},
|
||||
{ input: [0], output: [0]}
|
||||
];
|
||||
|
||||
var network = new architect.GRU(1,1,1);
|
||||
|
||||
// Train a sequence: 00100100..
|
||||
network.train(trainingSet, {
|
||||
log: 1,
|
||||
rate: 0.1,
|
||||
error: 0.005,
|
||||
iterations: 3000,
|
||||
clear: true
|
||||
});
|
||||
```
|
||||
[Run it here yourself!](https://jsfiddle.net/dzywa15x/)
|
||||
22
node_modules/neataptic/mkdocs/templates/docs/builtins/hopfield.md
generated
vendored
Normal file
22
node_modules/neataptic/mkdocs/templates/docs/builtins/hopfield.md
generated
vendored
Normal file
@@ -0,0 +1,22 @@
|
||||
description: How to use the Hopfield network in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: feed-forward, neural-network, hopfield, architecture
|
||||
|
||||
> This network might be removed soon
|
||||
|
||||
The hopfield architecture is excellent for remembering patterns. Given an input, it will output the most similar pattern it was trained. The output will always be binary, due to the usage of the `Activation.STEP` function.
|
||||
|
||||
```javascript
|
||||
var network = architect.Hopfield(10);
|
||||
var trainingSet = [
|
||||
{ input: [0, 1, 0, 1, 0, 1, 0, 1, 0, 1], output: [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] },
|
||||
{ input: [1, 1, 1, 1, 1, 0, 0, 0, 0, 0], output: [1, 1, 1, 1, 1, 0, 0, 0, 0, 0] }
|
||||
];
|
||||
|
||||
network.train(trainingSet);
|
||||
|
||||
network.activate([0,1,0,1,0,1,0,1,1,1]); // [0, 1, 0, 1, 0, 1, 0, 1, 0, 1]
|
||||
network.activate([1,1,1,1,1,0,0,1,0,0]); // [1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
|
||||
```
|
||||
|
||||
The input for the training set must always be the same as the output.
|
||||
39
node_modules/neataptic/mkdocs/templates/docs/builtins/lstm.md
generated
vendored
Normal file
39
node_modules/neataptic/mkdocs/templates/docs/builtins/lstm.md
generated
vendored
Normal file
@@ -0,0 +1,39 @@
|
||||
description: How to use the Long Short-Term Memory network in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: recurrent, neural-network, LSTM, architecture
|
||||
|
||||
The [long short-term memory](http://en.wikipedia.org/wiki/Long_short_term_memory) is an architecture well-suited to learn from experience to classify, process and predict time series when there are very long time lags of unknown size between important events.
|
||||
|
||||
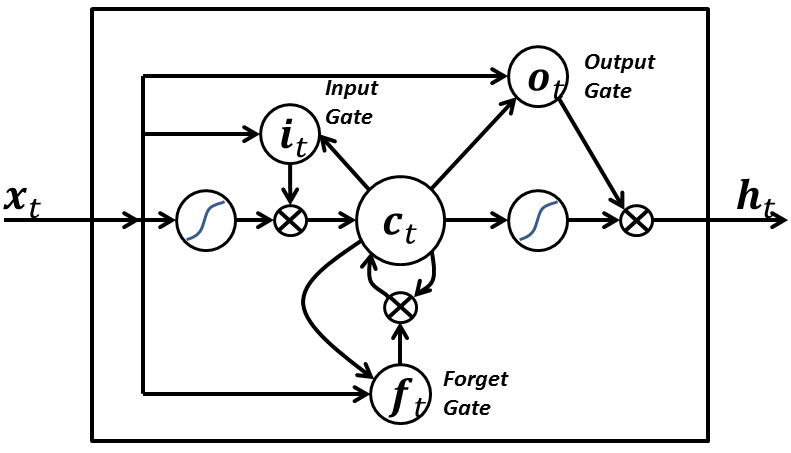
|
||||
|
||||
To use this architecture you have to set at least one input node, one memory block assembly (consisting of four nodes: input gate, memory cell, forget gate and output gate), and an output node.
|
||||
|
||||
```javascript
|
||||
var myLSTM = new architect.LSTM(2,6,1);
|
||||
```
|
||||
|
||||
Also you can set many layers of memory blocks:
|
||||
|
||||
```javascript
|
||||
var myLSTM = new architect.LSTM(2, 4, 4, 4, 1);
|
||||
```
|
||||
|
||||
That LSTM network has 3 memory block assemblies, with 4 memory cells each, and their own input gates, memory cells, forget gates and output gates.
|
||||
|
||||
You can pass options if desired like so:
|
||||
|
||||
```javascript
|
||||
var options = {
|
||||
memoryToMemory: false, // default is false
|
||||
outputToMemory: false, // default is false
|
||||
outputToGates: false, // default is false
|
||||
inputToOutput: true, // default is true
|
||||
inputToDeep: true // default is true
|
||||
};
|
||||
|
||||
var myLSTM = new architect.LSTM(2, 4, 4, 4, 1, options);
|
||||
```
|
||||
|
||||
While training sequences or timeseries prediction to a LSTM, make sure you set the `clear` option to true while training. [See an example of sequence prediction here.](https://jsfiddle.net/9t2787k5/4/)
|
||||
|
||||
This is an example of character-by-character typing by an LSTM: [JSFiddle](https://jsfiddle.net/k23zbf0f/8/)
|
||||
48
node_modules/neataptic/mkdocs/templates/docs/builtins/narx.md
generated
vendored
Normal file
48
node_modules/neataptic/mkdocs/templates/docs/builtins/narx.md
generated
vendored
Normal file
@@ -0,0 +1,48 @@
|
||||
description: How to use the Nonlinear Autoregressive Exogenous model network in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: recurrent, neural-network, NARX, architecture
|
||||
|
||||
Just like LSTM's, [NARX networks](https://en.wikipedia.org/wiki/Nonlinear_autoregressive_exogenous_model) are very good at timeseries prediction. That is because they use previous inputs and their corresponding output values as the next input to the hidden layer.
|
||||
|
||||

|
||||
|
||||
The constructor looks like this:
|
||||
|
||||
```js
|
||||
var network = new architect.NARX(inputSize, hiddenLayers, outputSize, previousInput, previousOutput);
|
||||
```
|
||||
|
||||
A quick explanation of each argument:
|
||||
|
||||
* `inputSize`: the amount of input nodes
|
||||
* `hiddenLayers`: an array containing hidden layer sizes, e.g. `[10,20,10]`. If only one hidden layer, can be a number (of nodes)
|
||||
* `outputSize`: the amount of output nodes
|
||||
* `previousInput`: the amount of previous inputs you want it to remember
|
||||
* `previousOutput`: the amount of previous outputs you want it to remember
|
||||
|
||||
Example:
|
||||
|
||||
```javascript
|
||||
var narx = new architect.NARX(1, 5, 1, 3, 3);
|
||||
|
||||
// Train the XOR gate (in sequence!)
|
||||
var trainingData = [
|
||||
{ input: [0], output: [0] },
|
||||
{ input: [0], output: [0] },
|
||||
{ input: [0], output: [1] },
|
||||
{ input: [1], output: [0] },
|
||||
{ input: [0], output: [0] },
|
||||
{ input: [0], output: [0] },
|
||||
{ input: [0], output: [1] },
|
||||
];
|
||||
|
||||
narx.train(trainingData, {
|
||||
log: 1,
|
||||
iterations: 3000,
|
||||
error: 0.03,
|
||||
rate: 0.05
|
||||
});
|
||||
```
|
||||
[Run it here](https://jsfiddle.net/wagenaartje/1o7t91yk/2/)
|
||||
|
||||
The NARX network type has 'constant' nodes. These nodes won't affect the weight of their incoming connections and their bias will never change. Please do note that mutation CAN change all of these.
|
||||
19
node_modules/neataptic/mkdocs/templates/docs/builtins/perceptron.md
generated
vendored
Normal file
19
node_modules/neataptic/mkdocs/templates/docs/builtins/perceptron.md
generated
vendored
Normal file
@@ -0,0 +1,19 @@
|
||||
description: How to use the Perceptron network in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: feed-forward, neural-network, perceptron, MLP, architecture
|
||||
|
||||
This architecture allows you to create multilayer perceptrons, also known as feed-forward neural networks. They consist of a sequence of layers, each fully connected to the next one.
|
||||
|
||||

|
||||
|
||||
You have to provide a minimum of 3 layers (input, hidden and output), but you can use as many hidden layers as you wish. This is a `Perceptron` with 2 neurons in the input layer, 3 neurons in the hidden layer, and 1 neuron in the output layer:
|
||||
|
||||
```javascript
|
||||
var myPerceptron = new architect.Perceptron(2,3,1);
|
||||
```
|
||||
|
||||
And this is a deep multilayer perceptron with 2 neurons in the input layer, 4 hidden layers with 10 neurons each, and 1 neuron in the output layer
|
||||
|
||||
```javascript
|
||||
var myPerceptron = new architect.Perceptron(2, 10, 10, 10, 10, 1);
|
||||
```
|
||||
35
node_modules/neataptic/mkdocs/templates/docs/builtins/random.md
generated
vendored
Normal file
35
node_modules/neataptic/mkdocs/templates/docs/builtins/random.md
generated
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
description: How to use the Random model network in Neataptic
|
||||
authors: Thomas Wagenaar
|
||||
keywords: recurrent, feed-forward, gates, neural-network, random, architecture
|
||||
|
||||
A random network is similar to a liquid network. This network will start of with a given pool of nodes, and will then create random connections between them. This network is really only useful for the initialization of the population for a genetic algorithm.
|
||||
|
||||
```javascript
|
||||
new architect.Random(input_size, hidden_size, output_size, options);
|
||||
```
|
||||
|
||||
* `input_size` : amount of input nodes
|
||||
* `hidden_size` : amount of nodes inbetween input and output
|
||||
* `output_size` : amount of output nodes
|
||||
|
||||
Options:
|
||||
* `connections` : amount of connections (default is `2 * hidden_size`, should always be bigger than `hidden_size`!)
|
||||
* `backconnections` : amount of recurrent connections (default is `0`)
|
||||
* `selfconnections` : amount of selfconnections (default is `0`)
|
||||
* `gates` : amount of gates (default is `0`)
|
||||
|
||||
For example:
|
||||
|
||||
```javascript
|
||||
var network = architect.Random(1, 20, 2, {
|
||||
connections: 40,
|
||||
gates: 4,
|
||||
selfconnections: 4
|
||||
});
|
||||
|
||||
drawGraph(network.graph(1000, 800), '.svg');
|
||||
```
|
||||
|
||||
will produce:
|
||||
|
||||
<img src="https://i.gyazo.com/a6a8076ce043f4892d0a77c6f816f0c0.png" width="100%"/>
|
||||
Reference in New Issue
Block a user